Redis線程模型的原理分析
一、概述
眾所周知,Redis是一個高性能的數據存儲框架,在高並發的系統設計中,Redis也是一個比較關鍵的組件,是我們提升系統性能的一大利器。深入去理解Redis高性能的原理顯得越發重要,當然Redis的高性能設計是一個系統性的工程,涉及到很多內容,本文重點關註Redis的IO模型,以及基於IO模型的線程模型。
我們從IO的起源開始,講述瞭阻塞IO、非阻塞IO、多路復用IO。基於多路復用IO,我們也梳理瞭幾種不同的Reactor模型,並分析瞭幾種Reactor模型的優缺點。基於Reactor模型我們開始瞭Redis的IO模型和線程模型的分析,並總結出Redis線程模型的優點、缺點,以及後續的Redis多線程模型方案。本文的重點是對Redis線程模型設計思想的梳理,捋順瞭設計思想,就是一通百通的事瞭。
註:本文的代碼都是偽代碼,主要是為瞭示意,不可用於生產環境。
二、網絡IO模型發展史
我們常說的網絡IO模型,主要包含阻塞IO、非阻塞IO、多路復用IO、信號驅動IO、異步IO,本文重點關註跟Redis相關的內容,所以我們重點分析阻塞IO、非阻塞IO、多路復用IO,幫助大傢後續更好的理解Redis網絡模型。
我們先看下面這張圖;
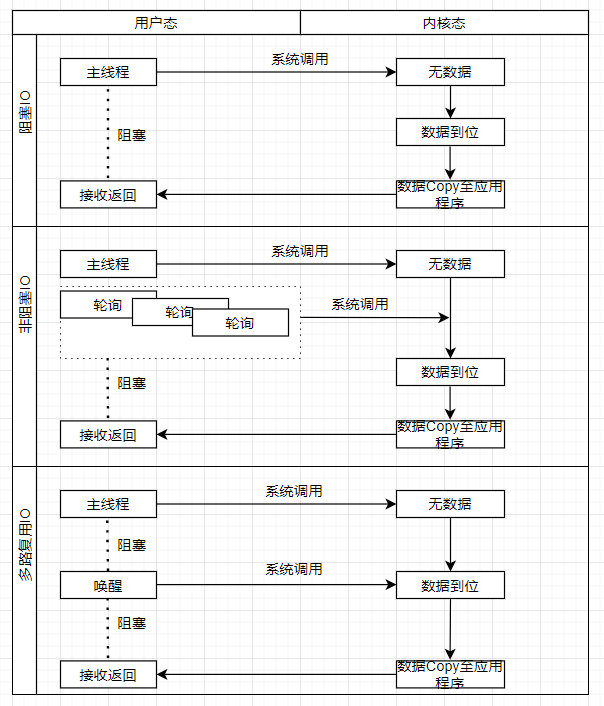
2.1 阻塞IO
我們經常說的阻塞IO其實分為兩種,一種是單線程阻塞,一種是多線程阻塞。這裡面其實有兩個概念,阻塞和線程。
- 阻塞:指調用結果返回之前,當前線程會被掛起,調用線程隻有在得到結果之後才會返回;
- 線程:系統調用的線程個數。
像建立連接、讀、寫都涉及到系統調用,本身是一個阻塞的操作。
2.1.1 單線程阻塞
服務端單線程來處理,當客戶端請求來臨時,服務端用主線程來處理連接、讀取、寫入等操作。
以下用代碼模擬瞭單線程的阻塞模式;
import java.net.Socket;
public class BioTest {
public static void main(String[] args) throws IOException {
ServerSocket server=new ServerSocket(8081);
while(true) {
Socket socket=server.accept();
System.out.println("accept port:"+socket.getPort());
BufferedReader in=new BufferedReader(new InputStreamReader(socket.getInputStream()));
String inData=null;
try {
while ((inData = in.readLine()) != null) {
System.out.println("client port:"+socket.getPort());
System.out.println("input data:"+inData);
if("close".equals(inData)) {
socket.close();
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
socket.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
}
我們準備用兩個客戶端同時發起連接請求、來模擬單線程阻塞模式的現象。同時發起連接,通過服務端日志,我們發現此時服務端隻接受瞭其中一個連接,主線程被阻塞在上一個連接的read方法上。


我們嘗試關閉第一個連接,看第二個連接的情況,我們希望看到的現象是,主線程返回,新的客戶端連接被接受。

從日志中發現,在第一個連接被關閉後,第二個連接的請求被處理瞭,也就是說第二個連接請求在排隊,直到主線程被喚醒,才能接收下一個請求,符合我們的預期。
此時不僅要問,為什麼呢?
主要原因在於accept、read、write三個函數都是阻塞的,主線程在系統調用的時候,線程是被阻塞的,其他客戶端的連接無法被響應。
通過以上流程,我們很容易發現這個過程的缺陷,服務器每次隻能處理一個連接請求,CPU沒有得到充分利用,性能比較低。如何充分利用CPU的多核特性呢?自然而然的想到瞭——多線程邏輯。
2.1.2 多線程阻塞
對工程師而言,代碼解釋一切,直接上代碼。
BIO多線程
package net.io.bio;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.ServerSocket;
import java.net.Socket;
public class BioTest {
public static void main(String[] args) throws IOException {
final ServerSocket server=new ServerSocket(8081);
while(true) {
new Thread(new Runnable() {
public void run() {
Socket socket=null;
try {
socket = server.accept();
System.out.println("accept port:"+socket.getPort());
BufferedReader in=new BufferedReader(new InputStreamReader(socket.getInputStream()));
String inData=null;
while ((inData = in.readLine()) != null) {
System.out.println("client port:"+socket.getPort());
System.out.println("input data:"+inData);
if("close".equals(inData)) {
socket.close();
}
}
} catch (IOException e) {
e.printStackTrace();
} finally {
}
}
}).start();
}
}
}
同樣,我們並行發起兩個請求;

兩個請求,都被接受,服務端新增兩個線程來處理客戶端的連接和後續請求。


我們用多線程解決瞭,服務器同時隻能處理一個請求的問題,但同時又帶來瞭一個問題,如果客戶端連接比較多時,服務端會創建大量的線程來處理請求,但線程本身是比較耗資源的,創建、上下文切換都比較耗資源,又如何去解決呢?
2.2 非阻塞
如果我們把所有的Socket(文件句柄,後續用Socket來代替fd的概念,盡量減少概念,減輕閱讀負擔)都放到隊列裡,隻用一個線程來輪訓所有的Socket的狀態,如果準備好瞭就把它拿出來,是不是就減少瞭服務端的線程數呢?
一起看下代碼,單純非阻塞模式,我們基本上不用,為瞭演示邏輯,我們模擬瞭相關代碼如下;
package net.io.bio;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.ServerSocket;
import java.net.Socket;
import java.net.SocketTimeoutException;
import java.util.ArrayList;
import java.util.List;
import org.apache.commons.collections4.CollectionUtils;
public class NioTest {
public static void main(String[] args) throws IOException {
final ServerSocket server=new ServerSocket(8082);
server.setSoTimeout(1000);
List<Socket> sockets=new ArrayList<Socket>();
while (true) {
Socket socket = null;
try {
socket = server.accept();
socket.setSoTimeout(500);
sockets.add(socket);
System.out.println("accept client port:"+socket.getPort());
} catch (SocketTimeoutException e) {
System.out.println("accept timeout");
}
//模擬非阻塞:輪詢已連接的socket,每個socket等待10MS,有數據就處理,無數據就返回,繼續輪詢
if(CollectionUtils.isNotEmpty(sockets)) {
for(Socket socketTemp:sockets ) {
try {
BufferedReader in=new BufferedReader(new InputStreamReader(socketTemp.getInputStream()));
String inData=null;
while ((inData = in.readLine()) != null) {
System.out.println("input data client port:"+socketTemp.getPort());
System.out.println("input data client port:"+socketTemp.getPort() +"data:"+inData);
if("close".equals(inData)) {
socketTemp.close();
}
}
} catch (SocketTimeoutException e) {
System.out.println("input client loop"+socketTemp.getPort());
}
}
}
}
}
}
系統初始化,等待連接;

發起兩個客戶端連接,線程開始輪詢兩個連接中是否有數據。

兩個連接分別輸入數據後,輪詢線程發現有數據準備好瞭,開始相關的邏輯處理(單線程、多線程都可)。

再用一張流程圖輔助解釋下(系統實際采用文件句柄,此時用Socket來代替,方便大傢理解)。

服務端專門有一個線程來負責輪詢所有的Socket,來確認操作系統是否完成瞭相關事件,如果有則返回處理,如果無繼續輪詢,大傢一起來思考下?此時又帶來瞭什麼問題呢。
CPU的空轉、系統調用(每次輪詢到涉及到一次系統調用,通過內核命令來確認數據是否準備好),造成資源的浪費,那有沒有一種機制,來解決這個問題呢?
2.3 IO多路復用
server端有沒專門的線程來做輪詢操作(應用程序端非內核),而是由事件來觸發,當有相關讀、寫、連接事件到來時,主動喚起服務端線程來進行相關邏輯處理。模擬瞭相關代碼如下;
IO多路復用
import java.net.InetSocketAddress;
import java.nio.ByteBuffer;
import java.nio.channels.SelectionKey;
import java.nio.channels.Selector;
import java.nio.channels.ServerSocketChannel;
import java.nio.channels.SocketChannel;
import java.nio.charset.Charset;
import java.util.Iterator;
import java.util.Set;
public class NioServer {
private static Charset charset = Charset.forName("UTF-8");
public static void main(String[] args) {
try {
Selector selector = Selector.open();
ServerSocketChannel chanel = ServerSocketChannel.open();
chanel.bind(new InetSocketAddress(8083));
chanel.configureBlocking(false);
chanel.register(selector, SelectionKey.OP_ACCEPT);
while (true){
int select = selector.select();
if(select == 0){
System.out.println("select loop");
continue;
}
System.out.println("os data ok");
Set<SelectionKey> selectionKeys = selector.selectedKeys();
Iterator<SelectionKey> iterator = selectionKeys.iterator();
while (iterator.hasNext()){
SelectionKey selectionKey = iterator.next();
if(selectionKey.isAcceptable()){
ServerSocketChannel server = (ServerSocketChannel)selectionKey.channel();
SocketChannel client = server.accept();
client.configureBlocking(false);
client.register(selector, SelectionKey.OP_READ);
//繼續可以接收連接事件
selectionKey.interestOps(SelectionKey.OP_ACCEPT);
}else if(selectionKey.isReadable()){
//得到SocketChannel
SocketChannel client = (SocketChannel)selectionKey.channel();
//定義緩沖區
ByteBuffer buffer = ByteBuffer.allocate(1024);
StringBuilder content = new StringBuilder();
while (client.read(buffer) > 0){
buffer.flip();
content.append(charset.decode(buffer));
}
System.out.println("client port:"+client.getRemoteAddress().toString()+",input data: "+content.toString());
//清空緩沖區
buffer.clear();
}
iterator.remove();
}
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
同時創建兩個連接;

兩個連接無阻塞的被創建;

無阻塞的接收讀寫;

再用一張流程圖輔助解釋下(系統實際采用文件句柄,此時用Socket來代替,方便大傢理解)。

當然操作系統的多路復用有好幾種實現方式,我們經常使用的select(),epoll模式這裡不做過多的解釋,有興趣的可以查看相關文檔,IO的發展後面還有異步、事件等模式,我們在這裡不過多的贅述,我們更多的是為瞭解釋Redis線程模式的發展。
三、NIO線程模型解釋
我們一起來聊瞭阻塞、非阻塞、IO多路復用模式,那Redis采用的是哪種呢?
Redis采用的是IO多路復用模式,所以我們重點來瞭解下多路復用這種模式,如何在更好的落地到我們系統中,不可避免的我們要聊下Reactor模式。
首先我們做下相關的名詞解釋;
Reactor:類似NIO編程中的Selector,負責I/O事件的派發;
Acceptor:NIO中接收到事件後,處理連接的那個分支邏輯;
Handler:消息讀寫處理等操作類。
3.1 單Reactor單線程模型

處理流程
- Reactor監聽連接事件、Socket事件,當有連接事件過來時交給Acceptor處理,當有Socket事件過來時交個對應的Handler處理。
優點
- 模型比較簡單,所有的處理過程都在一個連接裡;
- 實現上比較容易,模塊功能也比較解耦,Reactor負責多路復用和事件分發處理,Acceptor負責連接事件處理,Handler負責Scoket讀寫事件處理。
缺點
- 隻有一個線程,連接處理和業務處理共用一個線程,無法充分利用CPU多核的優勢。
- 在流量不是特別大、業務處理比較快的時候系統可以有很好的表現,當流量比較大、讀寫事件比較耗時情況下,容易導致系統出現性能瓶頸。
怎麼去解決上述問題呢?既然業務處理邏輯可能會影響系統瓶頸,那我們是不是可以把業務處理邏輯單拎出來,交給線程池來處理,一方面減小對主線程的影響,另一方面利用CPU多核的優勢。這一點希望大傢要理解透徹,方便我們後續理解Redis由單線程模型到多線程模型的設計的思路。
3.2 單Reactor多線程模型

這種模型相對單Reactor單線程模型,隻是將業務邏輯的處理邏輯交給瞭一個線程池來處理。
處理流程
- Reactor監聽連接事件、Socket事件,當有連接事件過來時交給Acceptor處理,當有Socket事件過來時交個對應的Handler處理。
- Handler完成讀事件後,包裝成一個任務對象,交給線程池來處理,把業務處理邏輯交給其他線程來處理。
優點
- 讓主線程專註於通用事件的處理(連接、讀、寫),從設計上進一步解耦;
- 利用CPU多核的優勢。
缺點
- 貌似這種模型已經很完美瞭,我們再思考下,如果客戶端很多、流量特別大的時候,通用事件的處理(讀、寫)也可能會成為主線程的瓶頸,因為每次讀、寫操作都涉及系統調用。
有沒有什麼好的辦法來解決上述問題呢?通過以上的分析,大傢有沒有發現一個現象,當某一個點成為系統瓶頸點時,想辦法把他拿出來,交個其他線程來處理,那這種場景是否適用呢?
3.3 多Reactor多線程模型

這種模型相對單Reactor多線程模型,隻是將Scoket的讀寫處理從mainReactor中拎出來,交給subReactor線程來處理。
處理流程
- mainReactor主線程負責連接事件的監聽和處理,當Acceptor處理完連接過程後,主線程將連接分配給subReactor;
- subReactor負責mainReactor分配過來的Socket的監聽和處理,當有Socket事件過來時交個對應的Handler處理;
Handler完成讀事件後,包裝成一個任務對象,交給線程池來處理,把業務處理邏輯交給其他線程來處理。
優點
- 讓主線程專註於連接事件的處理,子線程專註於讀寫事件吹,從設計上進一步解耦;
- 利用CPU多核的優勢。
缺點
- 實現上會比較復雜,在極度追求單機性能的場景中可以考慮使用。
四、Redis的線程模型
4.1 概述
以上我們聊瞭,IO網路模型的發展歷史,也聊瞭IO多路復用的reactor模式。那Redis采用的是哪種reactor模式呢?在回答這個問題前,我們先梳理幾個概念性的問題。
Redis服務器中有兩類事件,文件事件和時間事件。
- 文件事件:在這裡可以把文件理解為Socket相關的事件,比如連接、讀、寫等;
- 時間時間:可以理解為定時任務事件,比如一些定期的RDB持久化操作。
本文重點聊下Socket相關的事件。
4.2 模型圖
首先我們來看下Redis服務的線程模型圖;

IO多路復用負責各事件的監聽(連接、讀、寫等),當有事件發生時,將對應事件放入隊列中,由事件分發器根據事件類型來進行分發;
如果是連接事件,則分發至連接應答處理器;GET、SET等redis命令分發至命令請求處理器。
命令處理完後產生命令回復事件,再由事件隊列,到事件分發器,到命令回復處理器,回復客戶端響應。
4.3 一次客戶端和服務端的交互流程
4.3.1 連接流程

連接過程
- Redis服務端主線程監聽固定端口,並將連接事件綁定連接應答處理器。
- 客戶端發起連接後,連接事件被觸發,IO多路復用程序將連接事件包裝好後丟人事件隊列,然後由事件分發處理器分發給連接應答處理器。
- 連接應答處理器創建client對象以及Socket對象,我們這裡關註Socket對象,並產生ae_readable事件,和命令處理器關聯,標識後續該Socket對可讀事件感興趣,也就是開始接收客戶端的命令操作。
- 當前過程都是由一個主線程負責處理。
4.3.2 命令執行流程

SET命令執行過程
- 客戶端發起SET命令,IO多路復用程序監聽到該事件後(讀事件),將數據包裝成事件丟到事件隊列中(事件在上個流程中綁定瞭命令請求處理器);
- 事件分發處理器根據事件類型,將事件分發給對應的命令請求處理器;
- 命令請求處理器,讀取Socket中的數據,執行命令,然後產生ae_writable事件,並綁定命令回復處理器;
- IO多路復用程序監聽到寫事件後,將數據包裝成事件丟到事件隊列中,事件分發處理器根據事件類型分發至命令回復處理器;
- 命令回復處理器,將數據寫入Socket中返回給客戶端。
4.4 模型優缺點
以上流程分析我們可以看出Redis采用的是單線程Reactor模型,我們也分析瞭這種模式的優缺點,那Redis為什麼還要采用這種模式呢?
Redis本身的特性
命令執行基於內存操作,業務處理邏輯比較快,所以命令處理這一塊單線程來做也能維持一個很高的性能。
優點
- Reactor單線程模型的優點,參考上文。
缺點
- Reactor單線程模型的缺點也同樣在Redis中來體現,唯一不同的地方就在於業務邏輯處理(命令執行)這塊不是系統瓶頸點。
- 隨著流量的上漲,IO操作的的耗時會越來越明顯(read操作,內核中讀數據到應用程序。write操作,應用程序中的數據到內核),當達到一定閥值時系統的瓶頸就體現出來瞭。
Redis又是如何去解的呢?
哈哈~將耗時的點從主線程拎出來唄?那Redis的新版本是這麼做的嗎?我們一起來看下。
4.5 Redis多線程模式

Redis的多線程模型跟”多Reactor多線程模型“、“單Reactor多線程模型有點區別”,但同時用瞭兩種Reactor模型的思想,具體如下;
- Redis的多線程模型是將IO操作多線程化,本身邏輯處理過程(命令執行過程)依舊是單線程,借助瞭單Reactor思想,實現上又有所區分。
- 將IO操作多線程化,又跟單Reactor衍生出多Reactor的思想一致,都是將IO操作從主線程中拎出來。
命令執行大致流程
- 客戶端發送請求命令,觸發讀就緒事件,服務端主線程將Socket(為瞭簡化理解成本,統一用Socket來代表連接)放入一個隊列,主線程不負責讀;
- IO 線程通過Socket讀取客戶端的請求命令,主線程忙輪詢,等待所有 I/O 線程完成讀取任務,IO線程隻負責讀不負責執行命令;
- 主線程一次性執行所有命令,執行過程和單線程一樣,然後需要返回的連接放入另外一個隊列中,有IO線程來負責寫出(主線程也會寫);
- 主線程忙輪詢,等待所有 I/O 線程完成寫出任務。
五、總結
瞭解一個組件,更多的是要去瞭解他的設計思路,要去思考為什麼要這麼設計,做這種技術選型的背景是啥,對後續做系統架構設計有什麼參考意義等等。一通百通,希望對大傢有參考意義。
到此這篇關於Redis線程模型的原理分析的文章就介紹到這瞭,更多相關Redis線程模型內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Java基於TCP協議的Socket通信
- Java 實現簡單Socket 通信的示例
- Java 全面掌握網絡編程篇
- Java Socket實現簡易聊天室
- Java Socket上的Read操作阻塞問題詳解