Python通過樸素貝葉斯和LSTM分別實現新聞文本分類
一、項目背景
本項目來源於天池⼤賽,利⽤機器學習和深度學習等知識,對新聞⽂本進⾏分類。⼀共有14個分類類別:財經、彩票、房產、股票、傢居、教育、科技、社會、時尚、時政、體育、星座、遊戲、娛樂。
最終將測試集的預測結果上傳⾄⼤賽官⽹,可查看排名。評價標準為類別f1_score的均值,提交結果與實際測試集的類別進⾏對⽐。(不要求結果領先,但求真才實學)
二、數據處理與分析
本次大賽提供的材料是由csv格式編寫,隻需調用python中的pandas庫讀取即可。為瞭更直觀的觀察數據,我計算瞭文檔的平均長度,以及每個標簽分別對應的文檔。(sen字典與tag字典的獲取方法會在後文中展示,此步隻用來呈現數據分佈,運行時可先跳過)
import matplotlib.pyplot as plt
from tqdm import tqdm
import time
from numpy import *
import pandas as pd
print('count: 200000') #詞典sen中,每個標簽對應其所有句子的二維列表
print('average: '+str(sum([[sum(sen[i][j]) for j in range(len(sen[i]))] for i in sen])/200000))
x = []
y = []
for key,value in tag.items(): #詞典tag中,每個標簽對應該標簽下的句子數目
x.append(key)
y.append(value)
plt.bar(x,y)
plt.show()
最終我們得到瞭以下結果:
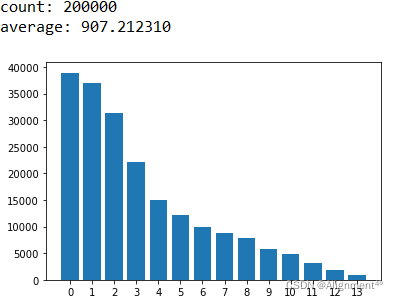
平均文檔長約907詞,每個標簽對應的文檔數從標簽0至13逐個減少。
三、基於機器學習的文本分類–樸素貝葉斯
1. 模型介紹
樸素貝葉斯分類器的基本思想是利用特征項和類別的聯合概率來估計給定文檔的類別概率。假設文本是基於詞的一元模型,即文本中當前詞的出現依賴於文本類別,但不依賴於其他詞及文本的長度,也就是說,詞與詞之間是獨立的。根據貝葉斯公式,文檔Doc屬於Ci類的概率為
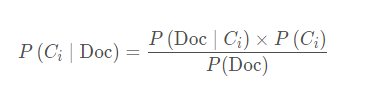
文檔Doc采用TF向量表示法,即文檔向量V的分量為相應特征在該文檔中出現的頻度,文檔Doc屬於Ci類文檔的概率為
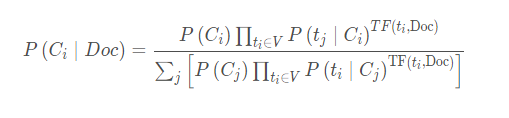
其中,TF(ti,Doc)是文檔Doc中特征ti出現的頻度,為瞭防止出現不在詞典中的詞導致概率為0的情況,我們取P(ti|Ci)是對Ci類文檔中特征ti出現的條件概率的拉普拉斯概率估計:
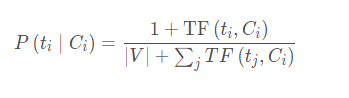
這裡,TF(ti,Ci)是Ci類文檔中特征ti出現的頻度,|V|為特征集的大小,即文檔表示中所包含的不同特征的總數目。
2. 代碼結構
我直接通過python自帶的open()函數讀取文件,並建立對應詞典,設定停用詞,這裡的停用詞選擇瞭words字典中出現在100000個文檔以上的所有詞。訓練集取前19萬個文檔,測試集取最後一萬個文檔。
train_df = open('./data/train_set.csv').readlines()[1:]
train = train_df[0:190000]
test = train_df[190000:200000]
true_test = open('./data/test_a.csv').readlines()[1:]
tag = {str(i):0 for i in range(0,14)}
sen = {str(i):{} for i in range(0,14)}
words={}
stop_words = {'4149': 1, '1519': 1, '2465': 1, '7539': 1, ...... }
接著,我們需要建立標簽詞典和句子詞典,用tqdm函數來顯示進度。
for line in tqdm(train_df):
cur_line = line.split('\t')
cur_tag = cur_line[0]
tag[cur_tag] += 1
cur_line = cur_line[1][:-1].split(' ')
for i in cur_line:
if i not in words:
words[i] = 1
else:
words[i] += 1
if i not in sen[cur_tag]:
sen[cur_tag][i] = 1
else:
sen[cur_tag][i] += 1
為瞭便於計算,我定義瞭如下函數,其中mul()用來計算列表中所有數的乘積,prob_clas() 用來計算P(Ci|Doc),用probability()來計算P(ti|Ci),在probability() 函數中,我將輸出結果中分子+1,分母加上字典長度,實現拉普拉斯平滑處理。
def mul(l):
res = 1
for i in l:
res *= i
return res
def prob_clas(clas):
return tag[clas]/(sum([tag[i] for i in tag]))
def probability(char,clas): #P(特征|類別)
if char not in sen[clas]:
num_char = 0
else:
num_char = sen[clas][char]
return (1+num_char)/(len(sen[clas])+len(words))
在做好所有準備工作,定義好函數後,分別對測試集中的每一句話計算十四個標簽對應概率,並將概率最大的標簽儲存在預測列表中,用tqdm函數來顯示進度。
PRED = []
for line in tqdm(true_test):
result = {str(i):0 for i in range(0,14)}
cur_line = line[:-1].split(' ')
clas = cur_tag
for i in result:
prob = []
for j in cur_line:
if j in stop_words:
continue
prob.append(log(probability(j,i)))
result[i] = log(prob_clas(i))+sum(prob)
for key,value in result.items():
if(value == max(result.values())):
pred = int(key)
PRED.append(pred)
最後把結果儲存在csv文件中上傳網站,提交後查看成績。(用此方法編寫的csv文件需要打開後刪去第一列再上傳)
res=pd.DataFrame()
res['label']=PRED
res.to_csv('test_TL.csv')
3. 結果分析
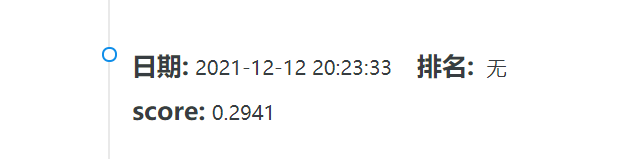
在訓練前19萬個文檔,測試後一萬個文檔的過程中,我不斷調整停用詞取用列表,分別用TF和TF-IDF向量表示法進行瞭測試,結果發現使用TF表示法準確性較高,最後取用停用詞為出現在十萬個文檔以上的詞。最終得出最高效率為0.622。

在提交至網站後,對五萬個文檔進行測試的F1值僅有 0.29左右,效果較差。
四、基於深度學習的文本分類–LSTM
1. 模型介紹
除瞭傳統的機器學習方法,我使用瞭深度學習中的LSTM(Long Short-Term Memory)長短期記憶網絡,來嘗試處理新聞文本分類,希望能有更高的準確率。LSTM它是一種時間循環神經網絡,適合於處理和預測時間序列中間隔和延遲相對較長的重要事件。LSTM 已經在科技領域有瞭多種應用。基於 LSTM 的系統可以學習翻譯語言、控制機器人、圖像分析、文檔摘要、語音識別圖像識別、手寫識別、控制聊天機器人、預測疾病、點擊率和股票、合成音樂等等任務。我采用深度學習庫Keras來建立LSTM模型,進行文本分類。
對於卷積神經網絡CNN和循環網絡RNN而言,隨著時間的不斷增加,隱藏層一次又一次地乘以權重W。假如某個權重w是一個接近於0或者大於1的數,隨著乘法次數的增加,這個權重值會變得很小或者很大,造成反向傳播時梯度計算變得很困難,造成梯度爆炸或者梯度消失的情況,模型難以訓練。也就是說一般的RNN模型對於長時間距離的信息記憶很差,因此LSTM應運而生。

LSTM長短期記憶網絡可以更好地解決這個問題。在LSTM的一個單元中,有四個顯示為黃色框的網絡層,每個層都有自己的權重,如以 σ 標記的層是 sigmoid 層,tanh是一個激發函數。這些紅圈表示逐點或逐元素操作。單元狀態在通過 LSTM 單元時幾乎沒有交互,使得大部分信息得以保留,單元狀態僅通過這些控制門(gate)進行修改。第一個控制門是遺忘門,用來決定我們會從單元狀態中丟棄什麼信息。第二個門是更新門,用以確定什麼樣的新信息被存放到單元狀態中。最後一個門是輸出門,我們需要確定輸出什麼樣的值。總結來說 LSTM 單元由單元狀態和一堆用於更新信息的控制門組成,讓信息部分傳遞到隱藏層狀態。
2. 代碼結構
首先是初始數據的設定和包的調用。考慮到平均句長約900,這裡取最大讀取長度為平均長度的2/3,即max_len為600,之後可通過調整該參數來調整學習效率。
from tqdm import tqdm
import pandas as pd
import time
import matplotlib.pyplot as plt
import seaborn as sns
from numpy import *
from sklearn import metrics
from sklearn.preprocessing import LabelEncoder,OneHotEncoder
from keras.models import Model
from keras.layers import LSTM, Activation, Dense, Dropout, Input, Embedding
from keras.optimizers import rmsprop_v2
from keras.preprocessing import sequence
from keras.callbacks import EarlyStopping
from keras.models import load_model
import os.path
max_words = 7549 #字典最大編號
# 可通過調節max_len調整模型效果和學習速度
max_len = 600 #句子的最大長度
stop_words = {}
接下來,我們定義一個將DataFrame的格式轉化為矩陣的函數。該函數輸出一個長度為600的二維文檔列表和其對應的標簽值。
def to_seq(dataframe):
x = []
y = array([[0]*int(i)+[1]+[0]*(13-int(i)) for i in dataframe['label']])
for i in tqdm(dataframe['text']):
cur_sentense = []
for word in i.split(' '):
if word not in stop_words: #最終並未采用停用詞列表
cur_sentense.append(word)
x.append(cur_sentense)
return sequence.pad_sequences(x,maxlen=max_len),y
接下來是模型的主體函數。該函數輸入測試的文檔,測試集的真值,訓練集和檢驗集,輸出預測得到的混淆矩陣。具體代碼介紹,見下列代碼中的註釋。
def test_file(text,value,train,val):
## 定義LSTM模型
inputs = Input(name='inputs',shape=[max_len])
## Embedding(詞匯表大小,batch大小,每個新聞的詞長)
layer = Embedding(max_words+1,128,input_length=max_len)(inputs)
layer = LSTM(128)(layer)
layer = Dense(128,activation="relu",name="FC1")(layer)
layer = Dropout(0.5)(layer)
layer = Dense(14,activation="softmax",name="FC2")(layer)
model = Model(inputs=inputs,outputs=layer)
model.summary()
model.compile(loss="categorical_crossentropy",optimizer=rmsprop_v2.RMSprop(),metrics=["accuracy"])
## 模型建立好之後開始訓練,如果已經保存訓練文件(.h5格式),則直接調取即可
if os.path.exists('my_model.h5') == True:
model = load_model('my_model.h5')
else:
train_seq_mat,train_y = to_seq(train)
val_seq_mat,val_y = to_seq(val)
model.fit(train_seq_mat,train_y,batch_size=128,epochs=10, #可通過epochs數來調整準確率和運算速度
validation_data=(val_seq_mat,val_y))
model.save('my_model.h5')
## 開始預測
test_pre = model.predict(text)
##計算混淆函數
confm = metrics.confusion_matrix(argmax(test_pre,axis=1),argmax(value,axis=1))
print(metrics.classification_report(argmax(test_pre,axis=1),argmax(value,axis=1)))
return confm
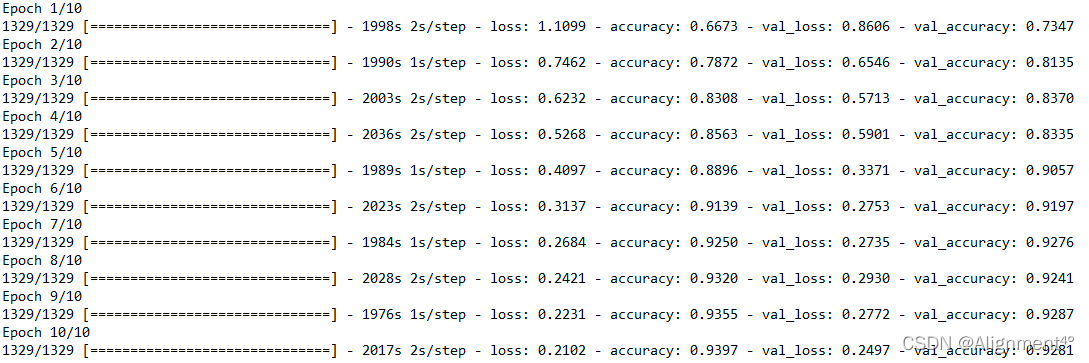
訓練過程如下圖所示。
為瞭更直觀的表現結果,定義如下函數繪制圖像。
def plot_fig(matrix):
Labname = [str(i) for i in range(14)]
plt.figure(figsize=(8,8))
sns.heatmap(matrix.T, square=True, annot=True,
fmt='d', cbar=False,linewidths=.8,
cmap="YlGnBu")
plt.xlabel('True label',size = 14)
plt.ylabel('Predicted label',size = 14)
plt.xticks(arange(14)+0.5,Labname,size = 12)
plt.yticks(arange(14)+0.3,Labname,size = 12)
plt.show()
return
最後,隻需要通過pandas讀取csv文件,按照比例分為訓練集、檢驗集和測試集(這裡選用比例為15:2:3),即可完成全部的預測過程。
def test_main():
train_df = pd.read_csv("./data/train_set.csv",sep='\t',nrows=200000)
train = train_df.iloc[0:150000,:]
test = train_df.iloc[150000:180000,:]
val = train_df.iloc[180000:,:]
test_seq_mat,test_y = to_seq(test)
Confm = test_file(test_seq_mat,test_y,train,val)
plot_fig(Confm)
在獲得預測結果最高的一組參數的選取後,我們訓練整個train_set文件,訓練過程如下,訓練之前需刪除已有的訓練文件(.h5),此函數中的test行可隨意選取,隻是為瞭滿足test_file()函數的變量足夠。此函數隻是用於訓練出學習效果最好的數據並儲存。
def train():
train_df = pd.read_csv("./data/train_set.csv",sep='\t',nrows=200000)
train = train_df.iloc[0:170000,:]
test = train_df.iloc[0:10000,:]
val = train_df.iloc[170000:,:]
test_seq_mat,test_y = to_seq(test)
Confm = test_file(test_seq_mat,test_y,train,val)
plot_fig(Confm)
在獲得最優的訓練數據後,我們就可以開始預測瞭。我們將競賽中提供的測試集帶入模型中,加載儲存好的訓練集進行預測,得到預測矩陣。再將預測矩陣中每一行的最大值轉化為對應的標簽,儲存在輸出列表中即可,最後將該列表寫入’test_DL.csv’文件中上傳即可。(如此生成的csv文件同上一個模型一樣,需手動打開刪除掉第一列)
def pred_file():
test_df = pd.read_csv('./data/test_a.csv')
test_seq_mat = sequence.pad_sequences([i.split(' ') for i in tqdm(test_df['text'])],maxlen=max_len)
inputs = Input(name='inputs',shape=[max_len])
## Embedding(詞匯表大小,batch大小,每個新聞的詞長)
layer = Embedding(max_words+1,128,input_length=max_len)(inputs)
layer = LSTM(128)(layer)
layer = Dense(128,activation="relu",name="FC1")(layer)
layer = Dropout(0.5)(layer)
layer = Dense(14,activation="softmax",name="FC2")(layer)
model = Model(inputs=inputs,outputs=layer)
model.summary()
model.compile(loss="categorical_crossentropy",optimizer=rmsprop_v2.RMSprop(),metrics=["accuracy"])
model = load_model('my_model.h5')
test_pre = model.predict(test_seq_mat)
pred_result = [i.tolist().index(max(i.tolist())) for i in test_pre]
res=pd.DataFrame()
res['label']=pred_result
res.to_csv('test_DL.csv')
整理後,我們隻需要註釋掉對應的指令行即可進行訓練或預測。
#如果想要訓練,取消下行註釋,訓練之前需先刪除原訓練文件(.h5) #train() #如果想要查看模型效果,取消下行註釋(訓練集:檢驗集:測試集=15:2:3) # test_main() #如果想預測並生成csv文件,取消下行註釋 # pred_file()
3. 結果分析
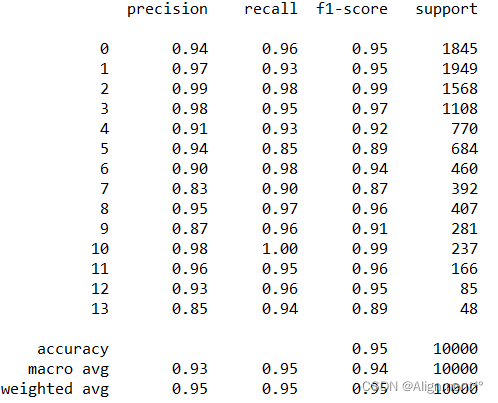
最終獲得的混淆矩陣如下圖所示,14個標簽預測的正確率均達到瞭80%以上,有11個標簽在90%以上,有6個標簽在95%以上。
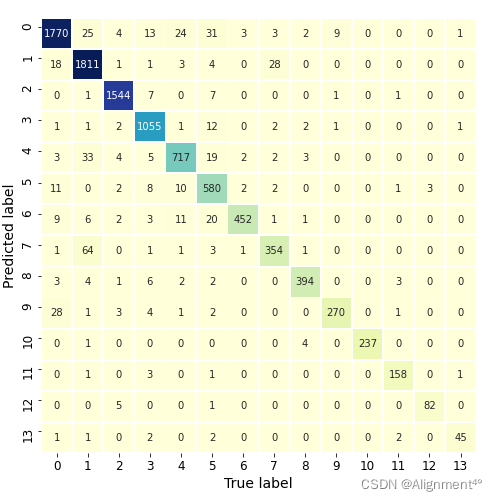
繪制出來的預測結果如下圖所示,可見預測效果相當理想,每個標簽的正確率都尤為可觀,預測錯誤的文本數相比於總量非常少。
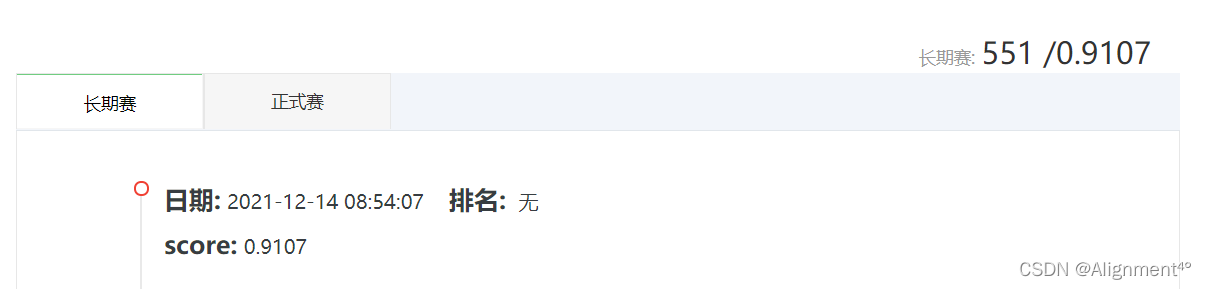
最終上傳網站得到結果,F1值達90%以上,效果較好。
五、小結
本實驗采用瞭傳統機器學習和基於LSTM的深度學習兩種方法對新聞文本進行瞭分類,在兩種方法的對比下,深度學習的效果明顯優於傳統的機器學習,並在競賽中取得瞭較好的成績(排名551)。但LSTM仍存在問題,一方面是RNN的梯度問題在LSTM及其變種裡面得到瞭一定程度的解決,但還是不夠;另一方面,LSTM計算費時,每一個LSTM的cell裡面都意味著有4個全連接層(MLP),如果LSTM的時間跨度很大,並且網絡又很深,這個計算量會很大,很耗時。
探尋更好的文本分類方法一直以來都是NLP在探索的方向,希望今後可以學習更多的分類方法,更多的機器學習和深度學習模型,提高分類效率。
到此這篇關於Python通過樸素貝葉斯和LSTM分別實現新聞文本分類的文章就介紹到這瞭,更多相關Python文本分類內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Pytorch實現LSTM案例總結學習
- 手把手教你使用TensorFlow2實現RNN
- tensorflow2.0實現復雜神經網絡(多輸入多輸出nn,Resnet)
- 基於Keras的擴展性使用
- Python實現K-近鄰算法的示例代碼