分佈式數據存儲系統的三要素
前言
CAP 理論指出,在分佈式系統中,不能同時滿足一致性、可用性和分區容錯性,指導瞭分佈式數據存儲系統的設計。
隨著數據量和訪問量的增加,單機性能已經不能滿足用戶需求,分佈式集群存儲成為一種常用方式。把數據分佈在多臺存儲節點上,可以為大規模應用提供大容量、高性能、高可用、 高擴展的存儲服務。而分佈式存儲系統就是其具體實現。
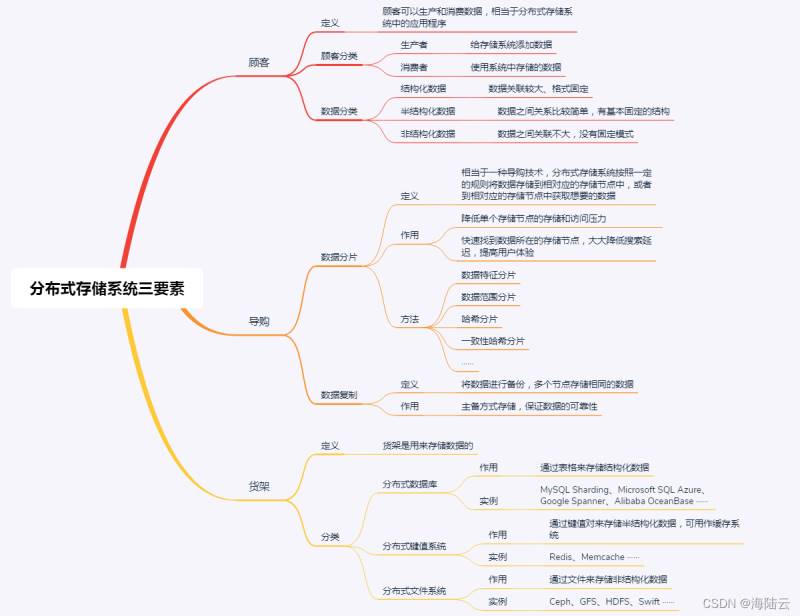
分佈式存儲系統的關鍵三要素:顧客、導購與貨架。
什麼是分佈式數據存儲系統?
分佈式存儲系統的核心邏輯:將用戶需要存儲的數據根據某種規則存儲到不同的機器上,當用戶想要獲取指定數據時,再按照規則到存儲數據的機器裡獲取。
如下圖所示,當用戶(即應用程序)想要訪問數據 D,分佈式操作引擎通過一些映射方式,比如 Hash、一致性 Hash、數據范圍分類等,將用戶引導至數據 D 所屬的存儲節點獲取數據。
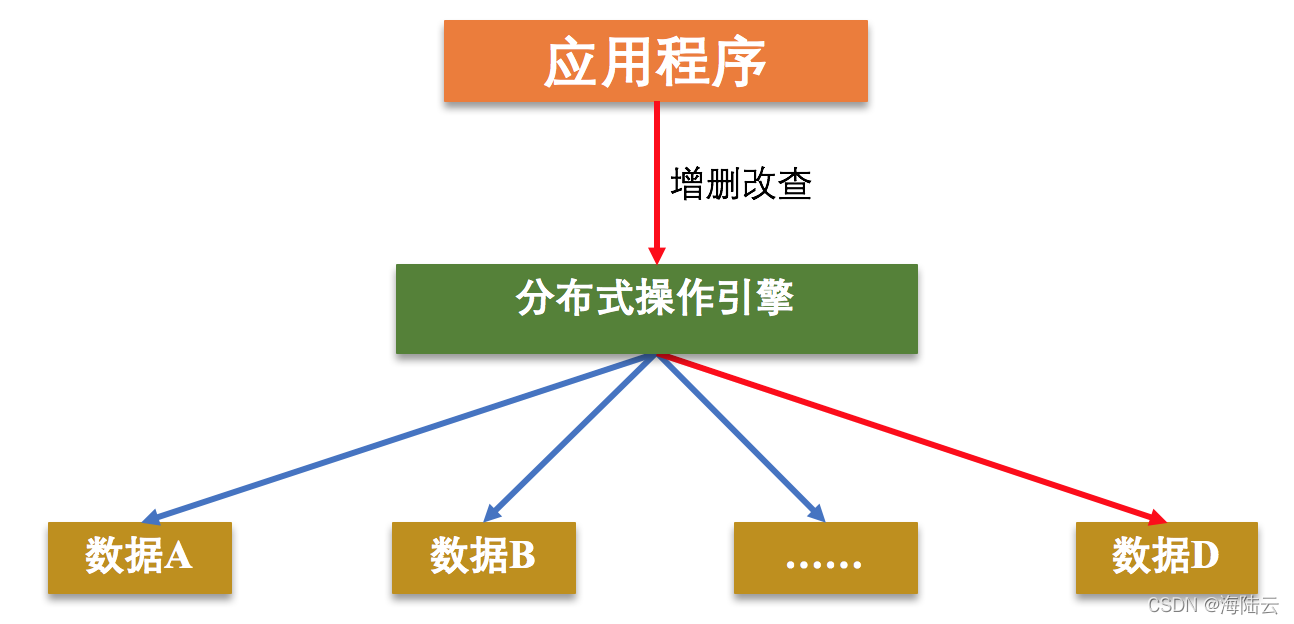
獲取數據的整個過程與商店購物的過程類似,顧客到商店購物時,導購會根據顧客想要購買的商品引導顧客到相應的貨架,然後顧客從這 個貨架上獲取要購買的商品,完成購物。這裡的顧客就是圖中的應用程序,導購就相當於分佈式操作引擎,它會按照一定的規則找到相應的貨架,貨架就是存儲數據的不同機器節點。
這個過程就是分佈式存儲系統中獲取數據的通用流程,顧客、導購和貨架組成瞭分佈式存儲系統的三要素,分別對應著分佈式領域中的數據生產者 / 消費者、數據索引和數據存儲。
分佈式數據存儲系統三要素
顧客就是數據的生產者和消費者,顧客代表兩類角色,生產者會生產數據(比如, 商店購物例子中的供貨商就屬於生產類顧客),將數據存儲到分佈式數據存儲系統中,消費者是從分佈式數據存儲系統中獲取數據進行消費(比如,商店購物例子中購買商品的用戶就屬於消費類顧客);導購就是數據索引,將訪問數據的請求轉發到數據所在的存儲節點;貨架就是存儲設備,用於存儲數據。
顧客:生產和消費數據
顧客相當於分佈式存儲系統中的應用程序,而數據是應用程序的原動力。根據數據的產生和使用,顧客分為生產者和消費者兩種類型。生產者負責給存儲系統添加數據,而消費者則可以使用系統中存儲的數據。
就像是火車票存儲系統,鐵路局就相當於生產者類型的顧客,而乘客就相當於消費者類型的顧客。鐵路局將各個線路的火車票信息發佈到訂票網站的後臺數據庫中,乘客通過訂票網站訪問數據庫,來進行查詢餘票、訂票、退票等操作。

生產者和消費者生產和消費的數據通常是多種多樣的,不同應用場景中數據的類型、格式等都不一樣。根據數據的特征,這些不同的數據通常被劃分為三類:結構化數據、半結構化數據和非結構化數據:
結構化數據:指關系模型數據,其特征是數據關聯較大、格式固定。火車票信息比如起點站、終點站、車次、票價等,就是一種結構化數據。結構化數據具有格式固定的特征,因此一般采用分佈式關系數據庫進行存儲和查詢。半結構化數據:指非關系模型的,有基本固定結構模式的數據,其特征是數據之間關系比較簡單。比如 HTML 文檔,使用標簽書寫內容。半結構化數據大多可以采用鍵值對形式來表示,比如 HTML 文檔可以將標簽設置為 key,標簽對應的內容可以設置為 value,因此一般采用分佈式鍵值系統進行存儲和使用。非結構化數據:指沒有固定模式的數據,其特征是數據之間關聯不大。比如文本數據就是一種非結構化數據。這種數據可以存儲到文檔中,通過 ElasticSearch(一個分佈式全文搜索引擎)等進行檢索。
導購:確定數據位置
導購是分佈式存儲系統必不可少的要素,如果沒有導購, 顧客就需要逐個貨架去尋找自己想要的商品。如果去訂票網站訂火車票,按照自己的需求點擊查詢車票後,系統會逐個掃描分佈式存儲系統中每臺機器的數據,尋找你想要購買的火車票。如果系統中存儲的數據不多,響應時間也不會太長,畢竟計算機的速度還是很快的;但如果數據分佈在幾千臺甚至上萬臺機器中,系統逐個機器掃描後再給你響應,嚴重影響購票體驗。
因此在分佈式存儲系統中,必須有相應的數據導購,否則系統響應會很慢,效率很低。為解決這個問題,數據分片技術就走入瞭分佈式存儲系統中。
數據分片技術:指分佈式存儲系統按照一定的規則將數據存儲到相對應的存儲節點中,或者到相對應的存儲節點中獲取想要的數據,優點:
降低單個存儲節點的存儲和訪問壓力;通過規定好的規則快速找到數據所在的存儲節點,從而大大降低搜索延遲,提高用戶體驗。
當鐵路局發佈各個線路的火車票信息時,會按照一定規則存儲到相應的機器中, 比如北京到上海的火車票存儲到機器 A 中,西安到重慶的火車票存儲到機器 B 中。當乘客查詢火車票時,系統就可以根據查詢條件迅速定位到相對應的存儲機器,然後將數據返回給用戶,響應時間就大大縮短瞭。如圖所示,當查詢北京 – 上海的火車票相關信息時,可以與機器 A 進行數據交互。

例子中按照數據起點、終點的方式劃分數據,將數據分為幾部分存儲到不同的機器節點中,就是數據分片技術的一種。當查詢數據時,系統可以根據查詢條件迅速找到對應的存儲節點,從而實現快速響應。 還有其他很多數據分片的方案。比如,按照數據范圍,采用哈希映射、一致性哈希環等對數據劃分。
針對數據范圍的數據分片方案:按照某種規則劃分數據范圍,然後將在這個范圍內的數據歸屬到一個集合中。這就好比數學中通常講的整數區間,比如 1~1000 的整數,[1,100] 的整數屬於一個子集、[101,1000] 的整數屬於另一個子集。
對於前面講的火車票的案例,按照數據范圍分片的話,可以將屬於某條線的所有火車票數據劃分到一個子集或分區進行存儲,比如機器 A 存儲京廣線的火車票數據,機器 B 存儲京滬線的火車票數據。數據范圍的方案是按照范圍或區間進行存儲或查詢。
如圖所示,當用戶查詢北京 – 上海的火車票相關信息時,首先判斷查詢條件屬於哪個范圍,由於北京 – 上海的火車線路屬於京滬線,因此系統按照規則將查詢請求轉到存取京滬線火車票數據的機器 B,然後由機器 B 進行處理並給用戶返回響應結果。

為瞭提高分佈式系統的可用性與可靠性,除瞭通過數據分片減少單個節點的壓力外,數據復制也是一個非常重要的方法。數據復制是將數據進行備份,以使得多個節點存儲該數據。
數據復制和數據分片技術的區別:

數據 A 被拆分為兩部分存儲在兩個節點 Node1 和 Node2 上,屬於數據分片;數據 B 同一份完整的數據在兩個節點中均有存儲,就屬於數據復制。
在實際的分佈式存儲系統中,數據分片和數據復制通常是共存的:
數據通過分片方式存儲到不同的節點上,以減少單節點的性能瓶頸問題;而數據的存儲通常用主備方式保證可靠性,對每個節點上存儲的分片數據,采用主備方式存儲,以保證數據的可靠性。主備節點上數據的一致,是通過數據復制技術實現的。
Kafka 集群消息存儲架構圖,消息數據以 Partition(分區)進行存儲,一個 Topic(主題)可以由多個 Partition 進行存儲,Partition 可以分佈到多個 Broker 中;同時,Kafka 還提供瞭 Partition 副本機制(對分區存儲的信息進行備份,比如 Broker 1 中的 Topic-1 Partion-0 是對 Broker 0 上的 Topic-1 Partition-0 進行的備份),從而保證瞭消息存儲的可靠性。

貨架:存儲數據
貨架是用來存儲數據的,因為數據是由顧客產生和消費的,因此貨架存儲的數據類型與顧客產生和消費的數據類型是一致的,即包括結構化數據、半結構化數據和非結構化數據。
針對這三種不同的數據類型,存儲“貨架”劃分為三種:
分佈式數據庫:通過表格來存儲結構化數據,方便查找。常用的分佈式數據庫有 MySQL Sharding、Microsoft SQL Azure、Google Spanner、Alibaba OceanBase 等。分佈式鍵值系統:通過鍵值對來存儲半結構化數據。常用的分佈式鍵值系統有 Redis、 Memcache 等,可用作緩存系統。分佈式存儲系統:通過文件、塊、對象等來存儲非結構化數據。常見的分佈式存儲系統 有 Ceph、GFS、HDFS、Swift 等。
對存儲介質的選擇,本質是選擇將數據存儲在磁盤還是內存(緩存) 上:
磁盤存儲量大,但 IO 開銷大,訪問速度較低,常用於存儲不經常使用的數據。比如,電商系統中,排名比較靠後或購買量比較少、甚至無人購買的商品信息,通常就存儲在磁盤上。內存容量小,訪問速度快,因此常用於存儲需要經常訪問的數據。比如,電商系統中, 購買量比較多或排名比較靠前的商品信息,通常就存儲在內存中。
知識擴展:業界主流的分佈式數據存儲系統有哪些?
貨架針對結構化數據、半結構化數據和非結構化數據,分別對應不同的“貨架”,即分佈式數據庫、分佈式鍵值系統和分佈式文件系統進行存儲。
主流的分佈式數據庫,主要包括 MySQL Sharding、SQL Azure、 Spanner、OceanBase 等。

主流的分佈式存儲系統,主要包括 Ceph、GFS、HDFS 和 Swift 等。

總結
分佈式數據存儲系統的三要素,即顧客、導購和貨架,對應到分佈式領域的術語就是數據生產者 / 消費者、數據索引和數據存儲。
顧客包括產生數據的顧客和消費數據的顧客兩類;導購是數據索引引擎,包括數據存儲時確定數據位置,以及獲取數據時確定數據所在位置;貨架負責數據存儲,包括磁盤、緩存等存儲介質等。
不同應用場景中,顧客產生的數據類型、格式等通常都不一樣。根據數據的特征,這些不同的數據可以被劃分為三類:結構化數據、半結構化數據和非結構化數據。與之相對應的,貨架也就是數據存儲系統,也包括三類:分佈式數據庫、分佈式鍵值系統和分佈式文件系統。
到此這篇關於分佈式數據存儲系統的三要素的文章就介紹到這瞭,更多相關分佈式數據存儲系統內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!