聚合函數和group by的關系詳解
前言
world:世界表格
continent:大洲名稱
name:國傢名稱
population:人口數量
聚合函數介紹
| sum() | 求和函數 |
|---|---|
| avg() | 求平均值函數 |
| max() | 求最大值函數 |
| min() | 求最小值函數 |
| count() | 求行數函數 |
group by介紹
group up + 字段名:規定哪個字段分組聚合
在單獨使用使用時,作用為分組去重 結果與distinct一樣,但是邏輯並不一樣:先對字段值相同的分為一個區,再將同區的拿出來進行分組,對應多少值就分多少組。分組就是將相同的字段進行剔除。簡單來說,就是打破瞭表格的格式生成瞭一張新的表格。
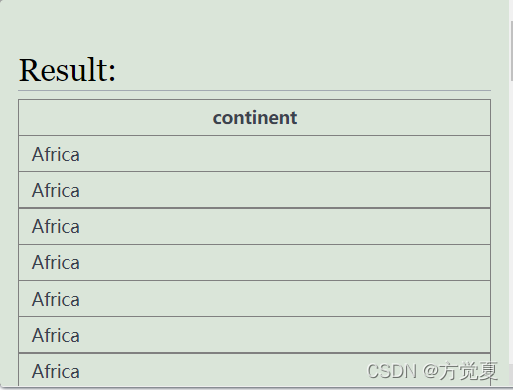

例如在上面這張表格就是執行group up後形成的分區結果,將相同的字段值分在瞭一起。下面的表格即是執行group by分組的結果,基於上面分區的結果,進行瞭去重的分組。

解釋聚合函數和group by的關系
那麼為什麼使用group by會形成這樣的結果呢?我們可以使用上聚合函數進行分析原因,執行下面一句SQL代碼。
select continent,count(name) from world group by continent
結果為
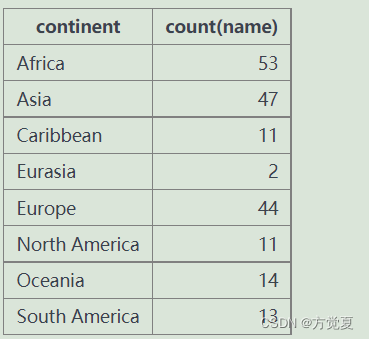
那麼我們試著將group by continent和continent去掉,得到以下結果
結果執行後查詢出來 count(name) 就隻是所有 name 這一列的行數的總合,並不能將每個大洲(continent)進行分組統計出來每個大洲所有國傢(name)的數量。
這就是聚合函數和group by聯合使用的作用,幫助聚合函數找到分組後的表格進行計算,在這一句
select continent,count(name) from world group by continent
SQL語句中是先進行瞭group by的分組,在進行select continent,最後在進行count(name),基於的就是group by後的分組進行計算。
我們可以將continent的字段名刪除,查看結果是否統一,作為印證。

很明顯我們無論有沒有將continent進行顯示,結果都是一樣的。
通過這次測試,我們就可以得出相對應的結論:在group up執行的時候,就已經將表格生成出來瞭,select隻是選擇展示和不展示出來而已,對於結果並沒有影響。而聚合函數的作用就是在生成出來新的表格內進行計算,舍棄瞭沒有進行分組的表格。
使用group by和聚合函數需要註意的地方
在使用group up子句時,select隻能使用聚合函數和group up引用的字段,否則會報錯!
嘗試執行下列SQL語句:
select continent,count(name),population from world group by continent

為什麼會出現報錯呢,因為在這句SQL語句中,group by已經先運行瞭,所以select不能出現在group by中沒有的字段,隻能基於在聚合依據的這個表中進行字段匹配。
總結
到此這篇關於聚合函數和group by的關系詳解的文章就介紹到這瞭,更多相關聚合函數和group by內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- MySQL 如何查找刪除重復行
- MySQL必備基礎之分組函數 聚合函數 分組查詢詳解
- MySQL去重中distinct和group by的區別淺析
- MySQL索引設計原則深入分析講解
- 詳解mysql數據去重的三種方式