Python爬取網頁的所有內外鏈的代碼
項目介紹
采用廣度優先搜索方法獲取一個網站上的所有外鏈。
首先,我們進入一個網頁,獲取網頁的所有內鏈和外鏈,再分別進入內鏈中,獲取該內鏈的所有內鏈和外鏈,直到訪問完所有內鏈未知。
代碼大綱
1、用class類定義一個隊列,先進先出,隊尾入隊,隊頭出隊;
2、定義四個函數,分別是爬取網頁外鏈,爬取網頁內鏈,進入內鏈的函數,以及調函數;
3、爬取百度圖片(https://image.baidu.com/),先定義兩個隊列和兩個數組,分別來存儲內鏈和外鏈;程序開始時,先分別爬取當前網頁的內鏈和外鏈,再分別入隊,對內鏈外鏈進行判斷,如果在數組中沒有存在,這添加到數組中;
4、接著調用deepLinks()函數,采用循環結構,如果當前內鏈數量不為空時,則對存儲內鏈的隊列進行出隊,並進入該內鏈中,再重復調用爬取網頁內鏈和網頁外鏈的函數,進行判斷網頁鏈接是否重復, 不重復的話,再分別將內鏈,外鏈加入到對應的隊列中,不斷迭代循環;
5、進入網頁內所有的內鏈,從中搜索出所有的外鏈並且存儲在隊列中,再輸出。
網站詳情

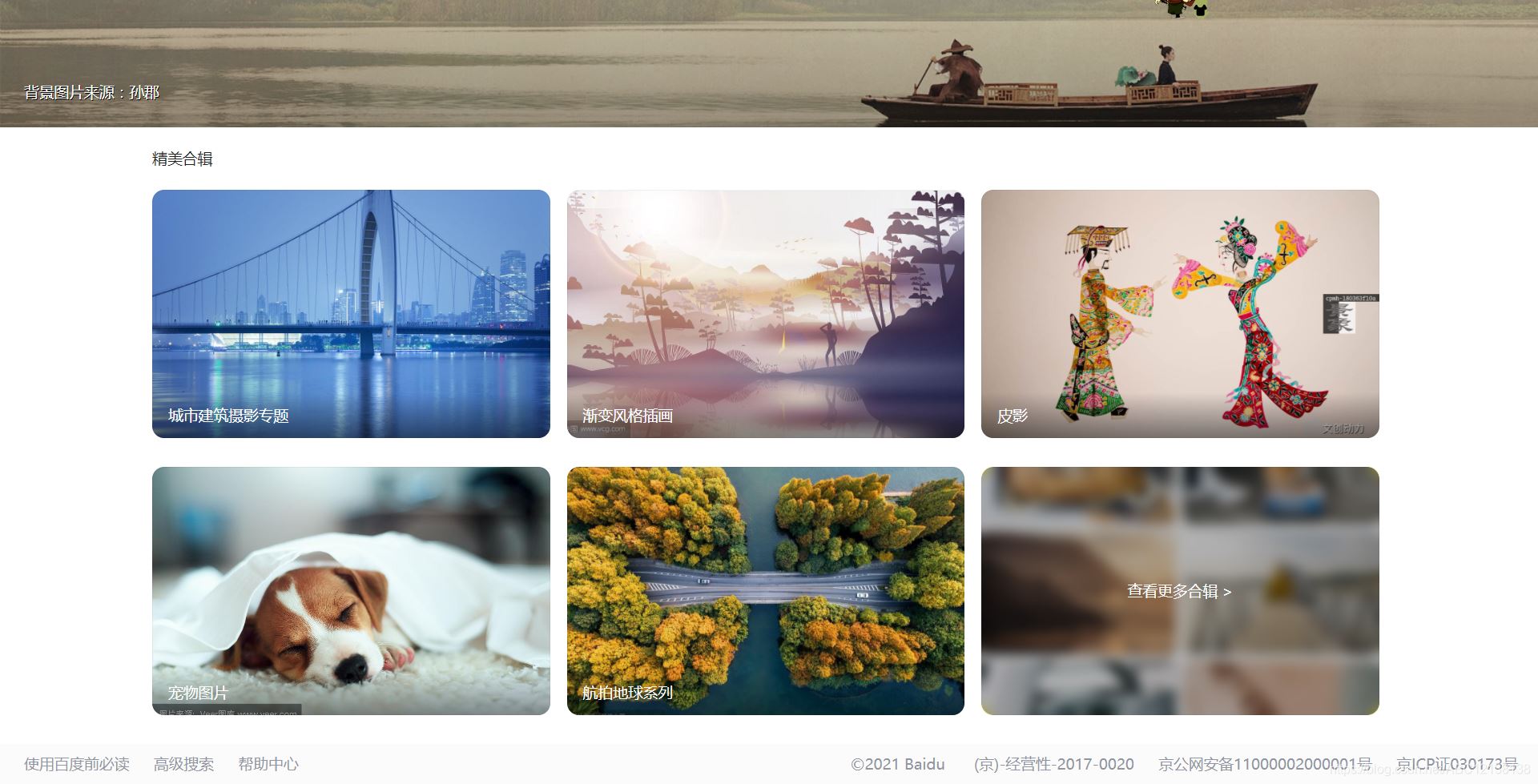
代碼詳情
隊列
隊列是一種特殊的線性表,單向隊列隻能在一端插入數據(後),另一端刪除數據(前);
它和棧一樣,隊列是一種操作受限制的線性表;
進行插入操作的稱為隊尾,進行刪除操作的稱為隊頭;
隊列中的數據被稱為元素;沒有元素的隊列稱為空隊列。
由於隻能一端刪除或者插入,所以隻有最先進入隊列的才能被刪除,因此又被稱為先進先出(FIFO—first in first out)線性表。
這裡我們用class類定義一個隊列,先進先出,隊尾入隊,隊頭出隊,該隊列要有定義以下功能:出隊、入隊、判斷是否為空、輸出隊列長度、返回隊頭元素。
class Queue(object):
#初始化隊列
def __init__(self):
self.items = []
#入隊
def enqueue(self, item):
self.items.append(item)
#出隊
def dequeue(self):
if self.is_Empty():
print("當前隊列為空!!")
else:
return self.items.pop(0)
#判斷是否為空
def is_Empty(self):
return self.items == []
#隊列長度
def size(self):
return len(self.items)
#返回隊頭元素,如果隊列為空的話,返回None
def front(self):
if self.is_Empty():
print("當前隊列為空!!")
else:
return self.items[len(self.items) - 1]
內鏈外鏈
內鏈外鏈的區別:
內鏈:是指同一網站域名下內容頁面之間的互相鏈接。
外鏈:是指在別的網站導入自己網站的鏈接,如友情鏈接、外鏈的搭建等。
通俗的講,內鏈即為帶有相同域名的鏈接,而外鏈的域名則不相同。
說到內鏈外鏈,那必然離不開urllib庫瞭,首先導入庫
from urllib.parse import urlparse
用urlparse模塊來解析url鏈接,urlparse()模塊將url拆分為6部分:
scheme (協議) netloc (域名) path (路徑) params (可選參數) query (連接鍵值對) fragment (特殊錨)
url='https://image.baidu.com/' a, b = urlparse(url).scheme, urlparse(url).netloc print(a) print(b) #-----------------輸出結果---------------------# https image.baidu.com
請求頭
Header來源 用瀏覽器打開需要訪問的網頁,按F12,點開network,再按提示按ctr+R,點擊name選擇網站名,再看到有一個右邊框第一個headers,找到request headers,這個就是瀏覽器的請求頭, 復制其中的user-agent,復制內容。
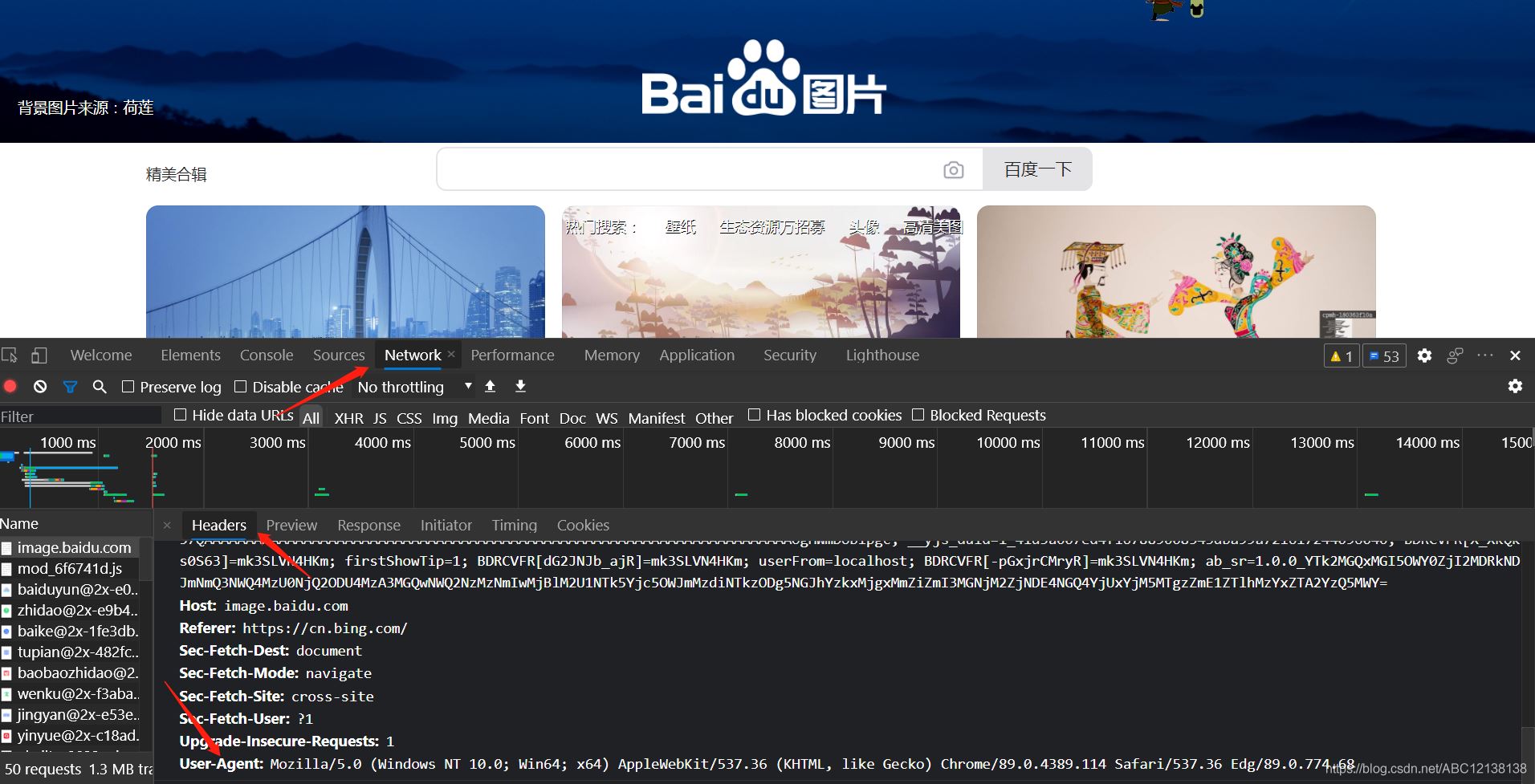
這裡的請求頭為:
headers_={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.68'}
html = requests.get(url,headers=headers_)
完整代碼
class Queue(object):
#初始化隊列
def __init__(self):
self.items = []
#入隊
def enqueue(self, item):
self.items.append(item)
#出隊
def dequeue(self):
if self.is_Empty():
print("當前隊列為空!!")
else:
return self.items.pop(0)
#判斷是否為空
def is_Empty(self):
return self.items == []
#隊列長度
def size(self):
return len(self.items)
#返回隊頭元素,如果隊列為空的話,返回None
def front(self):
if self.is_Empty():
print("當前隊列為空!!")
else:
return self.items[len(self.items) - 1]
#導入庫
from urllib.request import urlopen
from urllib.parse import urlparse
from bs4 import BeautifulSoup
import requests
import re
import urllib.parse
import time
import random
queueInt = Queue() #存儲內鏈的隊列
queueExt = Queue() #存儲外鏈的隊列
externalLinks = []
internalLinks = []
#獲取頁面中所有外鏈的列表
def getExterLinks(bs, exterurl):
#找出所有以www或http開頭且不包含當前URL的鏈接
for link in bs.find_all('a', href = re.compile
('^(http|www)((?!'+urlparse(exterurl).netloc+').)*$')):
#按照標準,URL隻允許一部分ASCII字符,其他字符(如漢字)是不符合標準的,
#我們的鏈接網址可能存在漢字的情況,此時就要進行編碼。
link.attrs['href'] = urllib.parse.quote(link.attrs['href'],safe='?=&:/')
if link.attrs['href'] is not None:
if link.attrs['href'] not in externalLinks:
queueExt.enqueue(link.attrs['href'])
externalLinks.append(link.attrs['href'])
print(link.attrs['href'])
# return externalLinks
#獲取頁面中所以內鏈的列表
def getInterLinks(bs, interurl):
interurl = '{}://{}'.format(urlparse(interurl).scheme,
urlparse(interurl).netloc)
#找出所有以“/”開頭的內部鏈接
for link in bs.find_all('a', href = re.compile
('^(/|.*'+urlparse(interurl).netloc+')')):
link.attrs['href'] = urllib.parse.quote(link.attrs['href'],safe='?=&:/')
if link.attrs['href'] is not None:
if link.attrs['href'] not in internalLinks:
#startsWith()方法用來判斷當前字符串是否是以另外一個給定的子字符串“開頭”的
if(link.attrs['href'].startswith('//')):
if interurl+link.attrs['href'] not in internalLinks:
queueInt.enqueue(interurl+link.attrs['href'])
internalLinks.append(interurl+link.attrs['href'])
elif(link.attrs['href'].startswith('/')):
if interurl+link.attrs['href'] not in internalLinks:
queueInt.enqueue(interurl+link.attrs['href'])
internalLinks.append(interurl+link.attrs['href'])
else:
queueInt.enqueue(link.attrs['href'])
internalLinks.append(link.attrs['href'])
# return internalLinks
def deepLinks():
num = queueInt.size()
while num > 1:
i = queueInt.dequeue()
if i is None:
break
else:
print('訪問的內鏈')
print(i)
print('找到的新外鏈')
# html = urlopen(i)
html=requests.get(i,headers=headers_)
time.sleep(random.random()*3)
domain1 = '{}://{}'.format(urlparse(i).scheme, urlparse(i).netloc)
bs = BeautifulSoup(html.content, 'html.parser')
getExterLinks(bs, domain1)
getInterLinks(bs, domain1)
def getAllLinks(url):
global num
# html = urlopen(url)
headers_={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/89.0.4389.114 Safari/537.36 Edg/89.0.774.68'}
html = requests.get(url,headers=headers_)
time.sleep(random.random()*3) #模擬人類行為,間隔隨機的時間
domain = '{}://{}'.format(urlparse(url).scheme, urlparse(url).netloc)
bs = BeautifulSoup(html.content, 'html.parser')
getInterLinks(bs, domain)
getExterLinks(bs, domain)
deepLinks()
getAllLinks('https://image.baidu.com/')
爬取結果
這裡我隻是截取一部分:


數組中的所有內鏈
internalLinks -------------輸出內容------------------ ['http://image.baidu.com', 'https://image.baidu.com/img/image/imageplus/index.html?fr=image', 'http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1567133149621_R&pv=&ic=0&nc=1&z=0&hd=0&latest=0©right=0&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&ie=utf-8&sid=&word=%25E5%25A3%2581%25E7%25BA%25B8', 'http://image.baidu.com/search/index?tn=baiduimage&ipn=r&ct=201326592&cl=2&lm=-1&st=-1&fm=result&fr=&sf=1&fmq=1461834053046_R&pv=&ic=0&nc=1&z=&se=1&showtab=0&fb=0&width=&height=&face=0&istype=2&itg=0&ie=utf-8&word=%25E5%25A4%25B4%25E5%2583%258F%23z=0&pn=&ic=0&st=-1&face=0&s=0&lm=-1', 'https://image.baidu.com/search/albumslist?tn=albumslist&word=%25E8%25AE%25BE%25E8%25AE%25A1%25E7%25B4%25A0%25E6%259D%2590&album_tab=%25E8%25AE%25BE%25E8%25AE%25A1%25E7%25B4%25A0%25E6%259D%2590&rn=15&fr=searchindex', 'https://image.baidu.com/search/albumsdetail?tn=albumsdetail&word=%25E5%259F%258E%25E5%25B8%2582%25E5%25BB%25BA%25E7%25AD%2591%25E6%2591%2584%25E5%25BD%25B1%25E4%25B8%2593%25E9%25A2%2598&fr=searchindex_album%2520&album_tab=%25E5%25BB%25BA%25E7%25AD%2591&album_id=7&rn=30', 'https://image.baidu.com/search/albumsdetail?tn=albumsdetail&word=%25E6%25B8%2590%25E5%258F%2598%25E9%25A3%258E%25E6%25A0%25BC%25E6%258F%2592%25E7%2594%25BB&fr=albumslist&album_tab=%25E8%25AE%25BE%25E8%25AE%25A1%25E7%25B4%25A0%25E6%259D%2590&album_id=409&rn=30', 'https://image.baidu.com/search/albumsdetail?tn=albumsdetail&word=%25E7%259A%25AE%25E5%25BD%25B1&fr=albumslist&album_tab=%25E8%25AE%25BE%25E8%25AE%25A1%25E7%25B4%25A0%25E6%259D%2590&album_id=394&rn=30', 'https://image.baidu.com/search/albumsdetail?tn=albumsdetail&word=%25E5%25AE%25A0%25E7%2589%25A9%25E5%259B%25BE%25E7%2589%2587&fr=albumslist&album_tab=%25E5%258A%25A8%25E7%2589%25A9&album_id=688&rn=30', 'https://image.baidu.com/search/albumsdetail?tn=albumsdetail&word=%25E8%2588%25AA%25E6%258B%258D%25E5%259C%25B0%25E7%2590%2583%25E7%25B3%25BB%25E5%2588%2597&fr=albumslist&album_tab=%25E8%25AE%25BE%25E8%25AE%25A1%25E7%25B4%25A0%25E6%259D%2590&album_id=312&rn=30', 'https://image.baidu.com/search/albumslist?tn=albumslist&word=%25E4%25BA%25BA%25E7%2589%25A9&album_tab=%25E4%25BA%25BA%25E7%2589%25A9&rn=15&fr=searchindex_album', 'http://image.baidu.com/static/html/advanced.html', 'https://image.baidu.com/', 'http://image.baidu.com/']
數組中的所有外鏈
externalLinks -------------輸出內容------------------ ['http://news.baidu.com/', 'https://www.hao123.com/', 'http://map.baidu.com/', 'https://haokan.baidu.com/?sfrom=baidu-top/', 'http://tieba.baidu.com/', 'https://xueshu.baidu.com/', 'http://www.baidu.com/more/', 'https://pan.baidu.com', 'https://zhidao.baidu.com', 'https://baike.baidu.com', 'https://baobao.baidu.com', 'https://wenku.baidu.com', 'https://jingyan.baidu.com', 'http://music.taihe.com', 'https://www.baidu.com', 'https://www.baidu.com/', 'http://www.baidu.com/duty/', 'http://www.baidu.com/search/image_help.html', 'http://www.beian.gov.cn/portal/registerSystemInfo?recordcode=11000002000001', 'http://help.baidu.com/question', 'http://www.baidu.com/search/jubao.html', 'http://www.baidu.com/search/faq_image.html%2305']
到此這篇關於Python爬取網頁的所有內外鏈的文章就介紹到這瞭,更多相關Python爬取網頁內外鏈內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- None Found