requests.gPython 用requests.get獲取網頁內容為空 ’ ’問題
下面先來看一個例子:
import requests
result=requests.get("http://data.10jqka.com.cn/financial/yjyg/")
result
輸出結果:
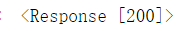
表示成功處理瞭請求,一般情況下都是返回此狀態碼; 報200代表沒問題
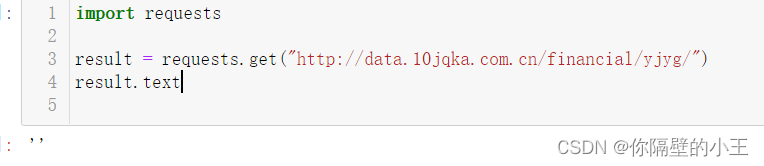
繼續運行,發現返回空值,在請求網頁爬取的時候,輸出的text信息中會出現抱歉,無法訪問等字眼,這就是禁止爬取,需要通過反爬機制去解決這個問題。headers是解決requests請求反爬的方法之一,相當於我們進去這個網頁的服務器本身,假裝自己本身在爬取數據。對反爬蟲網頁,可以設置一些headers信息,模擬成瀏覽器取訪問網站 。
一、如何設置headers
拿兩個常用的瀏覽器舉例:
1、QQ瀏覽器
界面 F12

點擊network 鍵入 CTRL+R
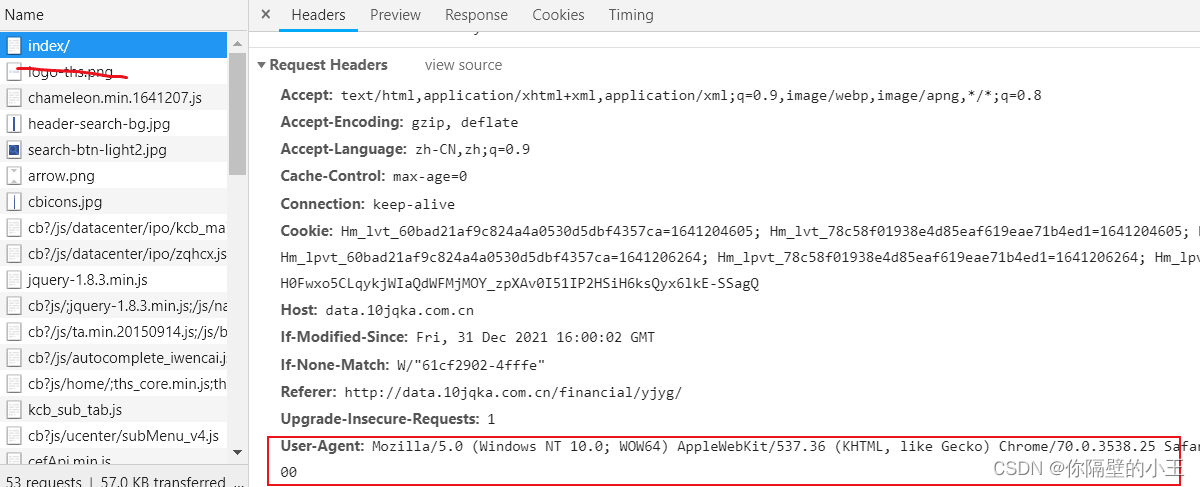
單擊第一個 最下邊就是我門需要的 把他設置成headers解決問題
2、Miscrosft edge
二、微軟自帶瀏覽器
同樣 F12 打開開發者工具
點擊網絡,CTRL+R
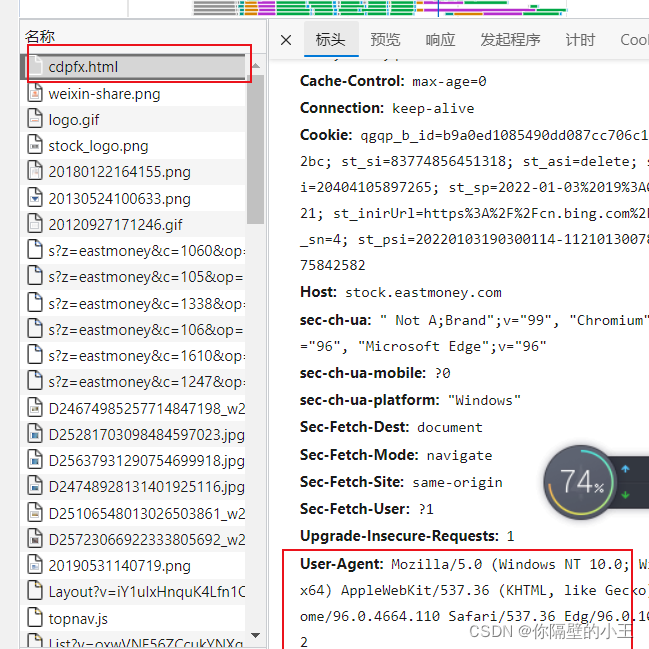
前文代碼修改:
import requests
ur="http://data.10jqka.com.cn/financial/yjyg/"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.25 Safari/537.36 Core/1.70.3880.400 QQBrowser/10.8.4554.400 '}
result = requests.get(ur, headers=headers)
result.text
成功解決不能爬取問題
到此這篇關於requests.gPython 用requests.get獲取網頁內容為空 ’ ’的文章就介紹到這瞭,更多相關requests.gPython 用requests.get獲取網頁內容為空 ’ ’內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python抓取數據到可視化全流程的實現過程
- python3 requests 各種發送方式詳解
- Python爬蟲報錯<response [406]>(已解決)
- python爬蟲實戰之制作屬於自己的一個IP代理模塊
- 詳解Python requests模塊