sklearn中make_blobs的用法詳情
sklearn中的make_blobs函數主要是為瞭生成數據集的,具體如下:
1.調用make_blobs
from sklearn.datasets import make_blobs
2.make_blobs的用法
data, label = make_blobs(n_features=2, n_samples=100, centers=3, random_state=3, cluster_std=[0.8, 2, 5])
n_features表示每一個樣本有多少特征值n_samples表示樣本的個數centers是聚類中心點的個數,可以理解為label的種類數random_state是隨機種子,可以固定生成的數據cluster_std設置每個類別的方差
下面舉例說明:
'''創建訓練的數據集''' from sklearn.datasets import make_blobs data, label = make_blobs(n_features=2, n_samples=100, centers=2, random_state=2019, cluster_std=[0.6,0.7] )
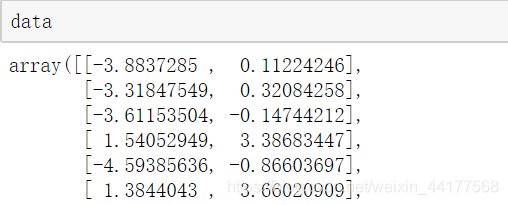
看看生成的數據集:
data有2個特征(n_features=2),樣本個數是100(n_samples=100)
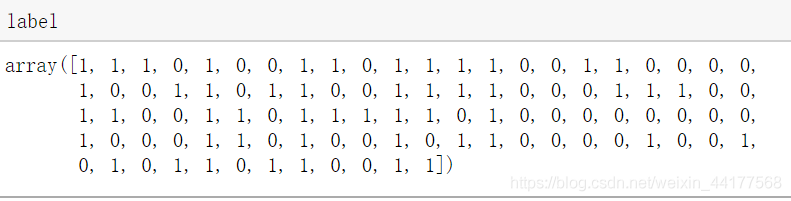
再看看生成的label:
label隻有0或者1(centers=2),維度是100
random_state給定數值後,每次生成的數據集就是固定的,方便後期復現,默認的是每次隨機生成,要註意一下!!
好瞭,這樣我們就擁有瞭一個自己想要的數據集,然後就可以開始後續的一些工作瞭!!!!
到此這篇關於sklearn中make_blobs的用法詳情的文章就介紹到這瞭,更多相關sklearn中make_blobs的用法內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- 使用Python和scikit-learn創建混淆矩陣的示例詳解
- Python集成學習之Blending算法詳解
- python 如何通過KNN來填充缺失值
- 人工智能——K-Means聚類算法及Python實現
- Python實現DBSCAN聚類算法並樣例測試