python 根據csv表頭、列號讀取數據的實現
根據csv表頭、列號讀取數據的實現
讀取csv文件
cvs數據截圖如下
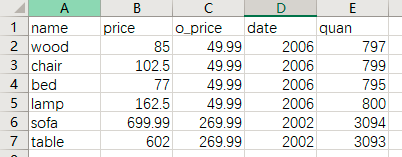
設置index_col=0,目的是設置第一列name為index(索引),方便下面示例演示
data = pandas.read_csv(input1, index_col=0)
輸出結果
price o_price date quan
name
wood 85.00 49.99 2006 797
chair 102.50 49.99 2006 799
bed 77.00 49.99 2006 795
lamp 162.50 49.99 2006 800
sofa 699.99 269.99 2002 3094
table 602.00 269.99 2002 3093
根據表頭獲取列數據
data[['o_price', 'quan'] # 或者 data.loc[:, ['o_price', 'quan']
輸出結果
o_price quan
name
wood 49.99 797
chair 49.99 799
bed 49.99 795
lamp 49.99 800
sofa 269.99 3094
table 269.99 3093
根據列號讀取列數據
data.iloc[:, [3, 4]]
輸出結果
date quan
name
wood 2006 797
chair 2006 799
bed 2006 795
lamp 2006 800
sofa 2002 3094
table 2002 3093
根據index名獲取行數據
data.loc[['wood', 'sofa'], :]
輸出結果
price o_price date quan
name
wood 85.00 49.99 2006 797
sofa 699.99 269.99 2002 3094
根據列號讀取行數據
data.iloc[[0, 1], :]
輸出結果
price o_price date quan
name
wood 85.0 49.99 2006 797
chair 102.5 49.99 2006 799
iloc和loc區別
loc是根據dataframe的具體標簽選取列,而iloc是根據標簽所在的位置,從0開始計數。
讀取csv文件並輸出特定列
其實,最開始好不容易輸出瞭指定列,結果第二天不小心刪瞭什麼東西,然後就一直報錯。
看上去和前一天能正常輸出的沒有什麼差別。折騰瞭一天多總算是找到問題是什麼瞭,是個很簡單的問題。
其實不是錯誤,隻是因為選用的讀取方式不同,所以一直報錯。
源代碼如下
import csv
import pandas as pd
sheet_name = "員工信息表.csv"
#數據文件有問題數據
with open(sheet_name,encoding = "utf-8",errors = "ignore") as f:
#可通過列名讀取列值,表中有空值
data= csv.DictReader(_.replace("\x00","") for _ in f)
headers = next(data)
print(headers)
for row in data:
print(row)
if row['員工狀態'] == '2':
print(row)
#不可通過列名讀取列值,通過第幾列來讀取
#data =csv.reader(_.replace("\x00","") for _ in f)
headers = next(data)
print(headers)
for row in data:
print(row)
if row[12]=='2':
print(row)
讀取csv文件需要采用:
with open(sheet_name,encoding = "utf-8",errors = "ignore") as f:
如果不加errors = "ignore"會報錯:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xbb in position 0: invalid start byte
通過csv.reader讀取csv文件,然後使用列名row['員工狀態']輸出列值會報錯:
“TypeError: list indices must be integers or slices, not str”
根據這個報錯百度瞭好久,一直沒有找到解決方法。
雖然現在最終效果達到瞭,但是並不清楚具體原因。
源數據表裡面問題好多啊,感覺需要先做數據清洗。唉!好難啊!
以上為個人經驗,希望能給大傢一個參考,也希望大傢多多支持WalkonNet。
推薦閱讀:
- 深入瞭解Python中的時間處理函數
- python pandas處理excel表格數據的常用方法總結
- python 使用xlsxwriter循環向excel中插入數據和圖片的操作
- python中pandas讀取csv文件時如何省去csv.reader()操作指定列步驟
- python中xlrd模塊的使用詳解