利用Python提取PDF文本的簡單方法實例
你好,一般情況下,Ctrl+C 是最簡單的方法,當無法 Ctrl+C 時,我們借助於 Python,以下是具體步驟:
第一步,安裝工具庫
1、tika — 用於從各種文件格式中進行文檔類型檢測和內容提取
2、wand — 基於 ctypes 的簡單 ImageMagick 綁定
3、pytesseract — OCR 識別工具
創建一個虛擬環境,安裝這些工具
python -m venv venv source venv/bin/activate pip install tika wand pytesseract
第二步,編寫代碼
假如 pdf 文件裡面既有文字,又有圖片,以下代碼可以直接識別文字:
import io
import pytesseract
import sys
from PIL import Image
from tika import parser
from wand.image import Image as wi
text_raw = parser.from_file("example.pdf")
print(text_raw['content'].strip())
這還不夠,我們還需要能失敗圖片的部分:
def extract_text_image(from_file, lang='deu', image_type='jpeg', resolution=300):
print("-- Parsing image", from_file, "--")
print("---------------------------------")
pdf_file = wi(filename=from_file, resolution=resolution)
image = pdf_file.convert(image_type)
image_blobs = []
for img in image.sequence:
img_page = wi(image=img)
image_blobs.append(img_page.make_blob(image_type))
extract = []
for img_blob in image_blobs:
image = Image.open(io.BytesIO(img_blob))
text = pytesseract.image_to_string(image, lang=lang)
extract.append(text)
for item in extract:
for line in item.split("\n"):
print(line)
合並一下,完整代碼如下:
import io
import sys
from PIL import Image
import pytesseract
from wand.image import Image as wi
from tika import parser
def extract_text_image(from_file, lang='deu', image_type='jpeg', resolution=300):
print("-- Parsing image", from_file, "--")
print("---------------------------------")
pdf_file = wi(filename=from_file, resolution=resolution)
image = pdf_file.convert(image_type)
for img in image.sequence:
img_page = wi(image=img)
image = Image.open(io.BytesIO(img_page.make_blob(image_type)))
text = pytesseract.image_to_string(image, lang=lang)
for part in text.split("\n"):
print("{}".format(part))
def parse_text(from_file):
print("-- Parsing text", from_file, "--")
text_raw = parser.from_file(from_file)
print("---------------------------------")
print(text_raw['content'].strip())
print("---------------------------------")
if __name__ == '__main__':
parse_text(sys.argv[1])
extract_text_image(sys.argv[1], sys.argv[2])
第三步,執行
假如 example.pdf 是這樣的:

在命令行這樣執行:
python run.py example.pdf deu | xargs -0 echo > extract.txt
最終 extract.txt 的結果如下:
— Parsing text example.pdf —
———————————
Title pure text
Content pure text
Slide 1
Slide 2
———————————
— Parsing image example.pdf —
———————————
Title pure text
Content pure text
Title in image
Text in image
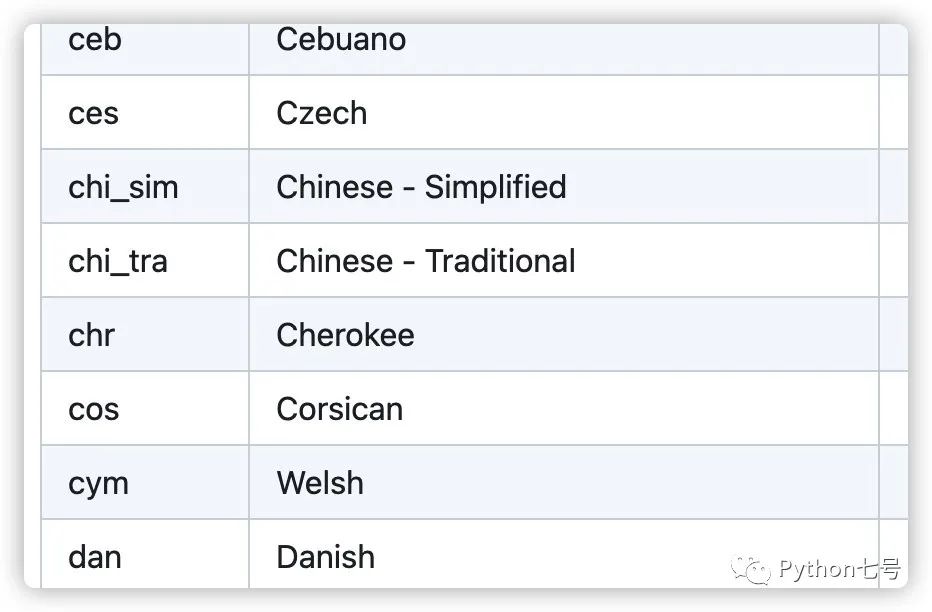
你可能會問,如果是簡體中文,那個 lang 參數傳遞什麼,傳 'chi_sim',其實是有官方說明的,鏈接如下:
https://github.com/tesseract-ocr/tessdoc/blob/main/Data-Files-in-different-versions.md
最後的話
從 PDF 中提取文本的腳本實現並不復雜,許多庫簡化瞭工作並取得瞭很好的效果
到此這篇關於利用Python提取PDF文本的簡單方法的文章就介紹到這瞭,更多相關Python提取PDF文本內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- python pytesseract庫的實例用法
- 如何利用Python識別圖片中的文字詳解
- 如何使用Python進行PDF圖片識別OCR
- Python 操作pdf pdfplumber讀取PDF寫入Exce
- python簡單驗證碼識別的實現過程