Mysql表連接的執行流程詳解
1. 前言
對於連接操作,驅動表和被驅動表的關聯條件我們放在on後面,如果額外增加對驅動表和被驅動表的過濾條件,放到on或者where後面都不會報錯,但是得到的結果集卻是不一樣的???
1.1 mysql連接的原理
眾所周知,mysql是基於嵌套循環連接(Nested-Loop Join,暫不考慮優化算法)算法來進行表之間的連接操作的,大致過程如下:
- 選取驅動表,使用與驅動表相關的過濾條件執行對驅動表的單表查詢;
- 對於查詢到的驅動表中的每一條紀錄,分別到被驅動表中查找匹配的紀錄。
偽代碼如下:
for each row in t1 { // 遍歷滿足對t1單表查詢結果集中的每一條紀錄
for each row in t2 { // 對於某條t1紀錄,遍歷滿足對t2單表查詢結果集中的每一條紀錄
if row satisfies join conditions, send to client
}
}
1.2 show warnings命令
我們寫的sql語句,在經過優化器優化後才會交給執行器執行,而show warnings命令則可以幫助我們獲得優化器優化後的sql。
2. 準備工作
表結構如下:
CREATE TABLE `student` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `stu_code` varchar(20) NOT NULL DEFAULT '', `stu_name` varchar(30) NOT NULL DEFAULT '', `stu_sex` varchar(10) NOT NULL DEFAULT '', `stu_age` int(10) NOT NULL DEFAULT '0', `stu_dept` varchar(30) NOT NULL DEFAULT '', PRIMARY KEY (`id`) USING BTREE, UNIQUE KEY `uq_stu_code` (`stu_code`) ) ENGINE=InnoDB AUTO_INCREMENT=43 DEFAULT CHARSET=utf8mb4 CREATE TABLE `course` ( `id` bigint(20) NOT NULL AUTO_INCREMENT, `cou_code` varchar(20) NOT NULL DEFAULT '', `cou_name` varchar(50) NOT NULL DEFAULT '', `cou_score` int(10) NOT NULL DEFAULT '0', `stu_code` varchar(20) NOT NULL DEFAULT '', PRIMARY KEY (`id`) USING BTREE, KEY `idx_stu_code_cou_code` (`stu_code`,`cou_code`) ) ENGINE=InnoDB AUTO_INCREMENT=19 DEFAULT CHARSET=utf8mb4
表數據如下:
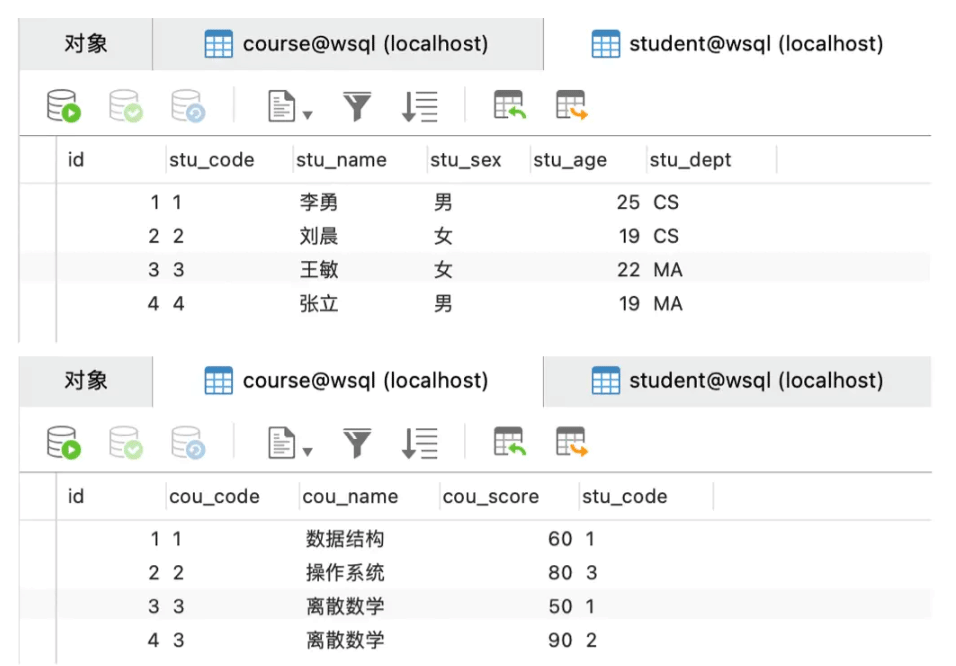
3. inner join內連接on、where的區別
sql如下:
select * from student inner join course on student.stu_code = course.stu_code and student.stu_code >= 3 and course.cou_score >= 80;
執行explain+sql命令:

執行show warnings命令:

分析:從show warnings分析來看,對於inner join連接,經過優化器優化後,on連接條件會轉化為where!也就是說內連接中的where和on是等價的。
4. left join左連接on、where的區別
4.1 where驅動表過濾條件
sql如下:
select * from student left join course on student.stu_code = course.stu_code where student.stu_code >= 3;
執行explain+sql命令:

執行show warnings命令:

結果集:

分析:從explain分析看出,student作為驅動表,把student.stu_code >= 3作為過濾條件進行全表掃描,然後把查詢到的每條紀錄的student.stu_code(也就是on條件裡面的)分別作為過濾條件讓被驅動表course做單表查詢。
4.2 on驅動表過濾條件
sql如下:
select * from student left join course on student.stu_code = course.stu_code and student.stu_code >= 3;
執行explain+sql命令:

執行show warnings命令:

結果集:

從結果集來看,student.stu_code >= 3並未生效,為什麼?
分析:從explain分析看出,student作為驅動表,做全表掃描,然後把查詢到的每條記錄的student.stu_code和student.stu_code >= 3(也就是on條件裡面的)分別做為過濾條件讓被驅動表做單表查詢;此時student.stu_code >= 3對驅動表是不過濾的,僅在連接被驅動表時生效,查詢不到符合紀錄而返回NULL!
4.3 on被驅動表過濾條件
sql如下:
select * from student left join course on student.stu_code = course.stu_code and course.cou_score >= 80;
執行explain+sql命令:

執行show warnings命令:

結果集:

分析:從explain分析看出,student作為驅動表,做全表掃描,然後把查詢到的每條記錄的student.stu_code和course.cou_score >= 80(也就是on條件裡面的)分別做為過濾條件讓被驅動表做單表查詢;
4.4 where被驅動表過濾條件
sql如下:

執行explain+sql命令:

執行show warnings命令:

結果集:

從show warnings分析來看?left join連接變成瞭inner join連接?
分析:從show warnings分析看出,如果被驅動表有過濾條件在where,那麼left join會被失效,被優化成inner join連接。所以被驅動表的過濾條件應該放在on而不是where。
5. 總結
其實,在內連接的基礎上引入外連接的概念,就是為瞭解決驅動表中的紀錄即使沒有在被驅動表中找到匹配的紀錄,仍要加入結果集的問題。所以對於外連接(外連接包括:左連接、右連接),被驅動表的過濾條件我們應該放在on!
到此這篇關於Mysql表連接的執行流程詳解的文章就介紹到這瞭,更多相關Mysql表連接 內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!