利用Python的pandas數據處理包將寬表變成窄表
前言
工作中經常會使用到將寬表變成窄表,例如這樣的形式
| 編號 | 編碼 | 單位1 | 單位2 | 單位3 | 單位4 | … | … | … | … | … | … |
| 1 | 編碼1… | 數量… | 數量… | 數量… | 數量… | … | … | … | … | … | … |
| 2 | 編碼2… | 數量… | 數量… | 數量… | 數量… | … | … | … | … | … | … |
然而工作中,這樣查看數據不夠方便,往往需要窄表的形式,如下:
| 編碼 | 單位 | 數量 |
| 編碼1 | 單位1 | 數量1 |
| 編碼2 | 單位2 | 數量2 |
| 編碼3 | 單位3 | 數量3 |
| …… | …… | …… |
嘗試使用Excel中的lookup函數進行填充,較為麻煩還不能直接實現功能,剛好在自學Python,就查閱瞭資料,看看能不能使用Python強大的數據處理功能來實現這個需求。
pandas簡介:pandas=pannel data+ data analysis;最初被作為金融數據分析工具而開發出來的,pandas為時間序列分析提供瞭很好的支持。同是也能夠靈活處理缺失數據,為數據分析操作提供瞭更為便捷的手段。
話不多說,直接上jupyter代碼。
1.引入包
供處理分析使用,這步so easy!
import pandas as pd import numpy as np import os
2.加載數據並顯示。常規操作。
data=pd.read_excel('test.xls')
data.head()
自己的測試數據存在test.xls中,這個文件存儲在路徑不必考慮,直接將原始存儲的文件在jupyter中點upload上傳到裡根目錄裡就可以。

顯示出來的,結果如圖所示:

3.關鍵操作,將寬表轉換為窄表
pd.set_option('display.max_rows', None)
df=pd.melt(data,id_vars="結算編碼",var_name="單位",value_name="數量")
df.head()
顯示結果如下, 可以看到數據顯示不全,還有空值,需要進一步進行處理操作。
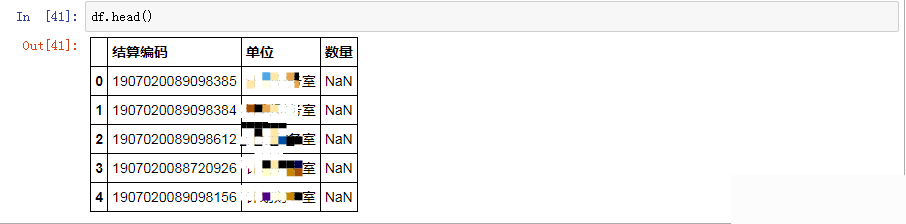
4.對空值進行處理
pd.set_option('display.max_rows', None)
#刪除所有值為空的行
df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
#how字段可選有any和all,any表示隻要有空值出現就刪除,all表示全部為空值才刪除;inplace字段表示是否替換掉原本的數據
#刪除所有值為空的列
df.dropna(axis="columns",how="all",inplace=False)
df.dropna()
處理後的結果可以看到,數據顯示齊全,並已過濾處理掉瞭空值。

5.導出存儲到Excel中
file_dir = 'D:/program/write/'
exists = os.path.exists(file_dir)
if not exists:
os.makedirs(file_dir)
df["結算編碼"] = df["結算編碼"].astype(str) #設置單元格格式
df.dropna().to_excel(os.path.join(file_dir,"result3.xlsx"), sheet_name="處理結果")
處理後的存儲結果:

結論:Python對數據處理分析真的操作簡單高效,後續可以多多嘗試使用Python來簡化辦公繁雜的程序,提升工作效率。
到此這篇關於利用Python的pandas數據處理包將寬表變成窄表的文章就介紹到這瞭,更多相關Python的pandas數據處理內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- pandas快速處理Excel,替換Nan,轉字典的操作
- python 文件讀寫和數據清洗
- python pandas處理excel表格數據的常用方法總結
- Pandas||過濾缺失數據||pd.dropna()函數的用法說明
- Python pandas處理缺失值方法詳解(dropna、drop、fillna)