Python實戰之疫苗研發情況可視化
一、安裝plotly庫
因為這部分內容主要是用plotly庫進行數據動態展示,所以要先安裝plotly庫
pip install plotly
除此之外,我們對數據的處理還用瞭numpy和pandas庫,如果你沒有安裝的話,可以用以下命令一行安裝
pip install plotly numpy pandas
#導入所需庫 import pandas as pd import numpy as np import plotly.express as px import plotly.graph_objects as go
二、疫苗研發情況
各國采用的疫苗品牌概覽
通過對各國衛生部門確認備案的疫苗品牌,展示各廠商的疫苗在全球的分佈
#讀取數據 locations=pd.read_csv(r'data/locations.csv')
locations
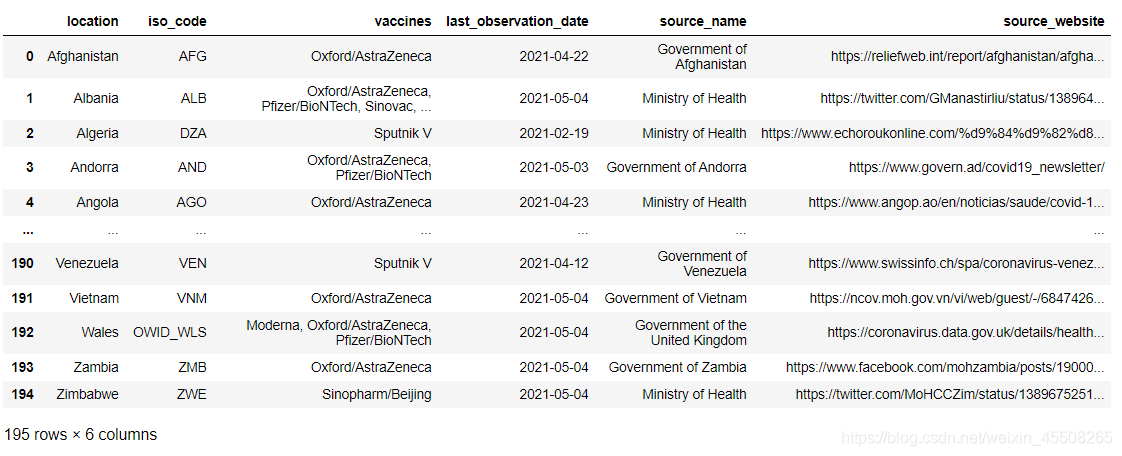
這裡我們的loacation中可以看到各個地方的疫苗和數據的來源與數據來源的網頁
三、數據處理
#發現數據中vaccines列中包含瞭多個品牌的情況,將這類數拆為多條
vaccines_by_country=pd.DataFrame()
for i in locations.iterrows():
df=pd.DataFrame({'Country':i[1].location,'vaccines':i[1].vaccines.split(',')})
vaccines_by_country=pd.concat([vaccines_by_country,df])
vaccines_by_country['vaccines']=vaccines_by_country.vaccines.str.strip()# 去掉空格
vaccines_by_country.vaccines.unique() # 查看疫苗的種類

四、可視化疫苗的分佈情況
#繪圖
fig=px.choropleth(vaccines_by_country,
locations='Country',
locationmode='country names',
color='vaccines',
facet_col='vaccines',
facet_col_wrap=3)
fig.update_layout(width=1200, height=1000)
fig.show()
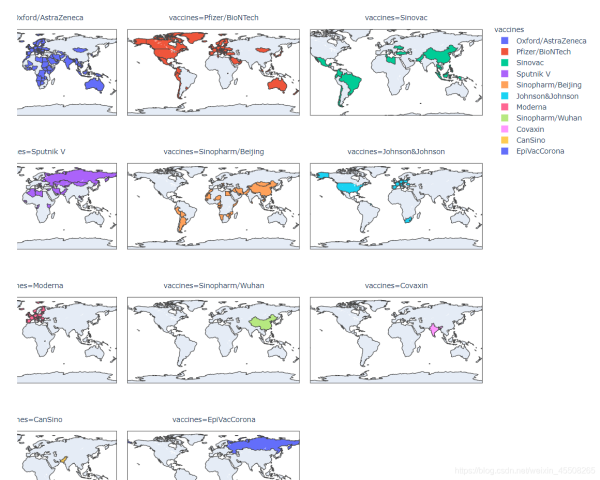
各品牌分佈:
- Pfizer/BioNTech 主要分佈於北美,南美的智利、厄瓜多爾,歐洲、沙特
- Sputnik V 主要分佈於俄羅斯、伊朗、巴基斯坦、非洲的阿爾及利亞以及南美的玻利維亞、阿根廷
- Oxford/AstraZeneca 主要分佈於歐洲、南亞、巴西
- Moderna 主要分佈在北美和歐洲
- Sinopharm/Beijing 主要分佈在中國、北非部分國傢和南美的秘魯
- Sinovac 主要分佈在中國、南亞、土耳其和南美
- Sinopharm/Wuhan 主要僅分佈於中國
- Covaxin 主要分佈於印度
綜上可以發現,全球采用最廣的仍是Pfizer/BioNTech,國產疫苗中Sinovac(北京科興疫苗)輸出到瞭較多國傢
五、各品牌疫苗上市情況(僅部分國傢)
根據數據集中提供的部分國傢20年12月以來各品牌疫苗接種情況,分析各品牌上市時間及市場占有情況
#讀取數據 vacc_by_manu=pd.read_csv(r'data/vaccinations-by-manufacturer.csv')
#定義函數,用於從原始數據中組織寬表
def query(df,country,date,vaccine):
try:
result=df.loc[(df.location==country)&(df.date==date)&(df.vaccine==vaccine)].total_vaccinations.iloc[0]
except:
result=np.nan
return result
vacc_by_manu

六、組織寬表
#組織寬表
vacc_combined=pd.DataFrame(columns=['location','date','Pfizer/BioNTech', 'Sinovac', 'Moderna', 'Oxford/AstraZeneca'])
for i in vacc_by_manu.location.unique():
for j in vacc_by_manu.date.unique():
for z in vacc_by_manu.vaccine.unique():
result=query(vacc_by_manu,i,j,z)
if vacc_combined.loc[(vacc_combined.location==i)&(vacc_combined.date==j)].empty:
result_df=pd.DataFrame({'location':i,'date':j,z:result},index=['new'])
vacc_combined=pd.concat([vacc_combined,result_df])
else:
vacc_combined.loc[(vacc_combined.location==i)&(vacc_combined.date==j),z]=result
vacc_combined
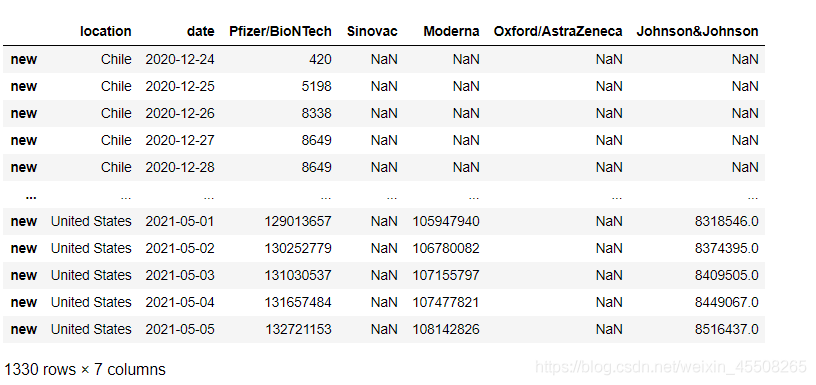
七、補全缺失數據
#補全缺失數據
temp=pd.DataFrame()
for i in vacc_combined.location.unique():#按國傢進行不全
r=vacc_combined.loc[vacc_combined.location==i]
r=r.fillna(method='ffill',axis=0)#先按最近一次的數據進行補全
temp=pd.concat([temp,r])#若沒有最近的數據,認為該項為0
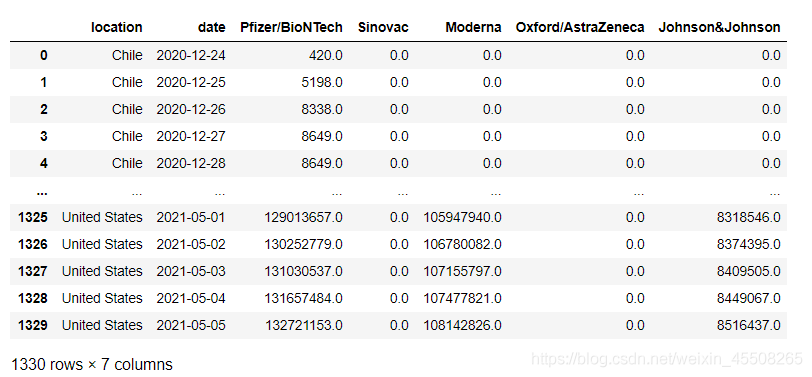
temp=temp.fillna(0).reset_index(drop=True)
temp
八、繪制堆疊柱狀圖
#繪制堆疊柱狀圖
fig=px.bar(temp,
x='location',
y=vacc_by_manu.vaccine.unique(),
animation_frame='date',
color_discrete_sequence=['#636efa','#19d3f3','#ab63fa','#00cc96']#為瞭查看方便,品牌顏色與前一部分對應
)
fig.show()
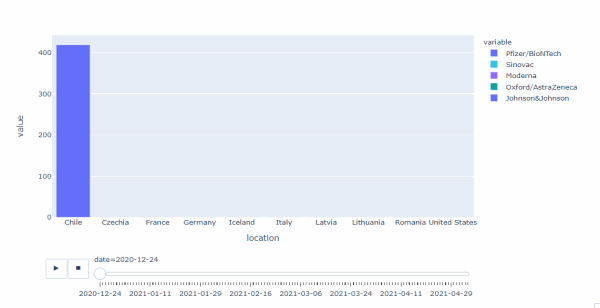
數據中主要涉及Pfizer/BioNTech、Sinovac、Moderna、Oxford/AstraZeneca 4個品牌,其中:
- Pfizer/BioNTech 上市時間最早,20年12月24日時即已經開始在智利接種瞭,之後在12月底開始在歐洲接種,21年1月12日開始在美國接種
- Sinovac 21年2月2日開始在智利接種Moderna 21年1月8日先在意大利開始接種,隨後12日即開始在美國大量接種,最終在歐洲及美國均大量接種
- Oxford/AstraZeneca 21年2月2日先在意大利開始接種,隨後即在歐洲開始接種
- 整體上看,Pfizer/BioNTech上市最早,且在全球占有份額最大,Moderna 隨後上市,主要占據美國和歐洲市場,Sinovac、Oxford/AstraZeneca上市均較晚,其中Sinovac占據瞭智利的大部分市場份額,而Oxford/AstraZeneca主要分佈於歐洲,且占份額很小
到此這篇關於Python實戰之疫苗研發情況可視化的文章就介紹到這瞭,更多相關Python疫苗研發情況可視化內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python可視化工具Plotly的應用教程
- python基礎之類方法和靜態方法
- pandas loc iloc ix用法詳細分析
- python讀寫xml文件實例詳解嘛
- 新手必學的mysql外鍵設置方式