Python數據分析之pandas讀取數據
一、三種數據文件的讀取

二、csv、tsv、txt 文件讀取
1)CSV文件讀取:
語法格式:pandas.read_csv(文件路徑)
CSV文件內容如下:
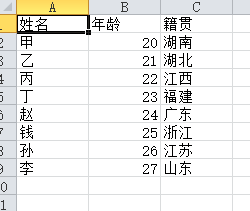
import pandas as pd file_path = "e:\\pandas_study\\test.csv" content = pd.read_csv(file_path) content.head() # 默認返回前5行數據 content.head(3) # 返回前3行數據 content.shape # 返回一個元組(總行數,總列數),總行數不包括標題行 content.index # 返回索引,是一個可迭代的對象<class 'pandas.core.indexes.range.RangeIndex'> content.column # 返回所有的列名 Index(['姓名', '年齡', '籍貫'], dtype='object') content.dtypes # 返回的是每列的數據類型 姓名 object 年齡 int64 籍貫 object dtype: object
2)CSV文件讀取:
語法格式:pandas.read_csv(文件路徑)
CSV文件內容如下:
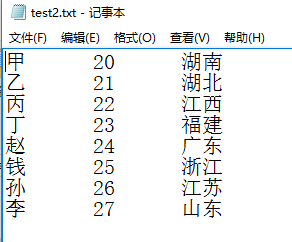
import pandas as pd file_path = "e:\\pandas_study\\test2.txt" content = pd.read_csv(file_path,sep='\t',header = None ,names= ['name','age','adress']) #參數說明: # header = None 表示沒有標題行 # sep='\t' 表示去除分割符中的空格 # names= ['name','age','adress'] ,列名依次自定義為'name','age','adress' content.head() # 默認返回前5行數據 content.head(3) # 返回前3行數據 content.shape # 返回一個元組(總行數,總列數),總行數不包括標題行 content.index # 返回索引,是一個可迭代的對象<class 'pandas.core.indexes.range.RangeIndex'> content.column # 返回所有的列名 Index(['姓名', '年齡', '籍貫'], dtype='object') content.dtypes # 返回的是每列的數據類型
三、excel文件讀取
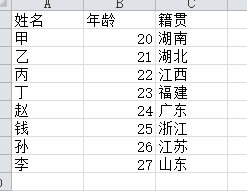
import pandas as pd file_path = "e:\\pandas_study\\test3.xlsx" content = pd.read_excel(file_path) content.head() # 默認返回前5行數據 content.head(3) # 返回前3行數據 content.shape # 返回一個元組(總行數,總列數),總行數不包括標題行 content.index # 返回索引,是一個可迭代的對象<class 'pandas.core.indexes.range.RangeIndex'> content.column # 返回所有的列名 Index(['姓名', '年齡', '籍貫'], dtype='object') content.dtypes # 返回的是每列的數據類型 姓名 object 年齡 int64 籍貫 object dtype: object
四、數據庫表格讀取
語法: pandas.read_sql(sql語句,數據庫連接對象)
數據對象的創建,可以根據pymysql,cx_oracle等模塊連接mysql或者oracle。
到此這篇關於Python數據分析之pandas讀取數據的文章就介紹到這瞭,更多相關pandas讀取數據內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python Pandas處理CSV文件的常用技巧分享
- 利用Pandas索引和選取數據方法詳解
- python中pandas對多列進行分組統計的實現
- python數學建模之三大模型與十大常用算法詳情
- Python Pandas讀取csv/tsv文件(read_csv,read_table)的區別