JVM知識總結之垃圾收集算法
一、什麼是垃圾
本文要講的是垃圾收集算法,那麼首先要確定的問題就是什麼是垃圾,也就是哪些對象是要被回收的,對此有兩種判斷方式:
1.1 引用計數算法
什麼樣的對象是要被回收的,很明顯,沒有被引用的對象才要被回收。因此在對象中加一個引用計數器,當有一個對象引用該對象的時候,計數器就加一,當引用結束後,計數器就減一,當計數器為0的時候,對象就可以被回收瞭。
1.1.1 優點
- 原理簡單
- 判斷效率高
1.1.2 缺點
- 需要花費額外的內存空間(引用計數器)
- 無法回收相互循環引用的對象:比如有對象A和對象B,A引用B,B引用A,兩對象的引用計數器都為1,理論上來說,沒有其他對象能夠引用到A和B瞭,因此這兩個對象應該被回收,然後按照引用計數算法的判斷,這兩個對象無法被回收。(要克服這個缺點,需要在代碼中做很多特殊處理)
1.2 可達性分析算法
因為引用計數算法的缺陷,各大主流的商用程序語言都采用可達性分析算法來判斷對象是否需要被回收。可達性顧名思義,是指對象跟對象之間有引用關系,此處有兩種引用關系:
- 對象A引用對象B,則稱對象A到對象B可達
- 對象A引用對象B,對象B引用對象C,對象A可以通過若幹個對象(此處為對象B)引用到對象C,則稱對象A到對象C可達。
要判斷一個對象是否可達,首先要有一個根對象,在Java中有一系列被稱為“GC Roots”的根對象作為起始節點集,任何從“GC Roots”不可達的對象都是需要被垃圾收集器回收的垃圾。
1.2.1 優點
可以有效解決引用計數算法的相互循環引用問題
二、什麼是引用
在討論什麼是垃圾的時候,多次提到引用一詞,那麼什麼是引用呢?
2.1 JDK1.2以前
按照書中的說法,在JDK1.2以前,引用的意思是:如果reference類型的數據中存儲的數值代表的是另外一塊內存的起始地址,就稱該reference數據是代表某塊內存、某個對象的引用。
在這種定義下可以發現,對於一個對象來說,就隻有未被引用和被引用兩種狀態瞭,但其實可以發現,在實際應用中,並不是一定要把對象回收掉的,書中有個詞就很貼切,“食之無味,棄之可惜”,我們想要的是當內存空間足夠的時候,把這部分本該回收的對象留著不回收,當內存不夠的時候,就將其回收。
2.2 JDK1.2之後
因此在JDK1.2之後,引用的概念就擴張到瞭以下四種:
- 強引用:指傳統意義上的引用,有強引用的對象是肯定不被回收的;
- 軟引用:用於描述一些還有用,但非必須的對象,當要發生內存溢出的時候,就會回收軟引用對象;
- 弱引用:用於描述非必須對象,強度比軟引用弱一點,當垃圾收集器開始工作,無論內存夠不夠都會回收弱引用對象;
- 虛引用:虛引用意思就是這個引用跟沒有一樣,對對象完全沒有印象,其存在的唯一作用就是在對象被垃圾收集器回收時能收到一個系統通知。
三、垃圾判斷全流程
按照書中所述,我畫瞭個流程圖,如下:
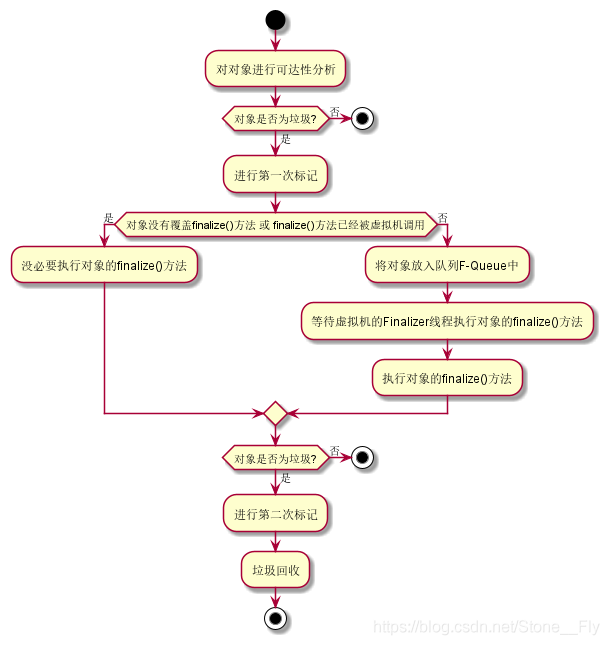
一個對象在被回收前,需要進行兩次標記,第一次進行可達性分析後,對象被垃圾收集器認為是垃圾,則對對象進行第一次標記,然後垃圾收集器會給予對象一次自救的機會,不然就沒必要兩次標記瞭,一次標記直接回收就好瞭。
我們都知道對象有個finalize()方法,自救的機會就在這個方法中,當第一次標記後,垃圾收集器會對對象做一次篩選,篩選條件是要不要執行對象的finalize()方法,如果開發者未對finalize()方法進行覆寫或者虛擬機已經執行過該對象的finalize()方法瞭,那麼自然就不用再執行瞭,反之則需要執行。
將篩選出來的需要執行finalize()方法的對象放入一個特定的隊列中,由虛擬機統一執行,如果finalize()方法中使得對象被別的對象引用瞭,導致可達性分析認為對象是可用的,那麼自救就成功瞭。
根據篩選的條件可以知道,對象的自救機會在整個程序中隻有一次,因為finalize()方法隻會被執行一次。
需要註意的是,官方明確申明不推薦使用finalize()方法,因為使用它的不確定性太大。對於資源清理等操作,try…catch語法可以做的更好。
四、垃圾收集算法
大多數虛擬機的垃圾收集都采用瞭分代收集的形式,這是因為三條經驗法則:
- 弱分代假說:絕大多數對象都是朝生夕死的;
- 強分代假說:熬過越多次垃圾收集過程的對象就越難以消亡
- 跨代引用假說:跨代引用相對於同代引用來說僅占極少數
因為對象的生存周期是不一樣的,所以我們不能對所有對象采用同一種垃圾收集算法,采用分代收集,將有共性的對象放在一個集合裡,會大大地提高垃圾收集效率。
按照上述經驗法則,可以將堆內存分為兩代:
- 新生代:對應弱分代假說
- 老年代:對應強分代假說
下面分別介紹三種垃圾收集算法:
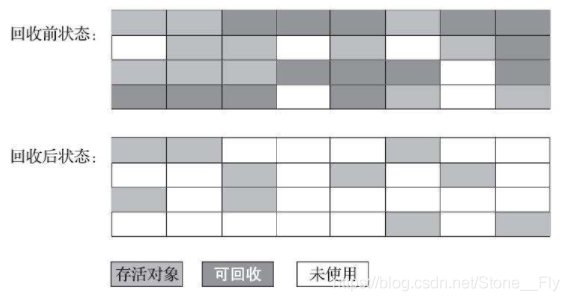
4.1 標記-清除算法
標記-清除算法是最基礎的垃圾收集算法,顧名思義,標記就是判斷對象是否是垃圾,也就是前面第四節講到的內容,清除就是統一回收垃圾,該算法有兩種執行過程:
- 標記所有需要被回收的對象,統一回收所有標記的對象;
- 標記所有存活對象,統一回收所有未被標記的對象。
標記-清除算法示意圖:
標記-清除算法有兩大缺點:
- 執行效率不穩定:標記和清除兩個過程的執行效率隨對象數量的增加而降低
- 內存空間碎片化:執行完標記和清除後,會產生大量的不連續的內存碎片,當分配大對象的時候,如果找不到足夠的連續內存,那麼會提前觸發下一次垃圾收集。
4.2 標記-復制算法
基於標記-清除算法的缺點,標記-復制算法將內存空間一分為二,兩塊內存空間等大,每次隻使用其中一塊內存空間,當這一塊內存空間用完瞭,就把存活的對象復制到另一塊內存空間中,然後一次性清理所有已使用的內存空間。
標記-復制算法示意圖:
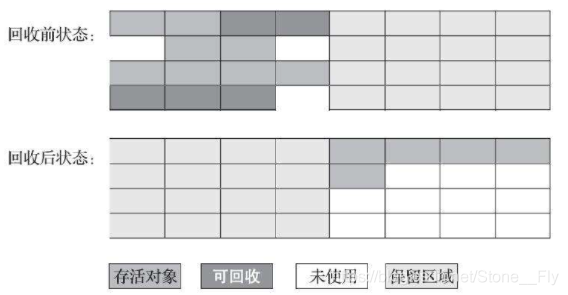
標記-復制算法解決瞭標記-清除算法面對大量可回收對象場景下的不足之處,面對這種情況,標記-復制算法隻需要將內存空間中的存活對象復制到另一半內存空間中,可以有效解決內存碎片的問題,在給對象分配內存的時候,隻需要移動堆頂指針按順序分配即可,不過這個算法也有缺點:
- 面對大量不可回收對象的時候,會產生大量內存間對象復制的開銷;
- 原先的內存空間縮小瞭一半,會造成嚴重的空間浪費
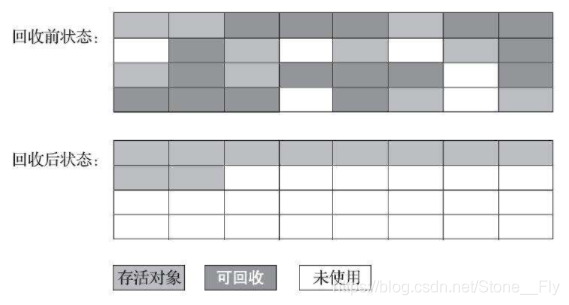
4.3 標記-整理算法
標記-復制算法不足以應對有大量存活對象的場景,因此就有瞭標記-整理算法,該算法的執行流程如下:
- 與其他算法一樣,首先對對象進行標記;
- 將所有存活對象往內存的一個方向移動;
- 直接清理掉邊界以外的內存
標記-整理算法示意圖:
標記-整理算法同樣可以解決內存碎片化問題,並且不會造成空間浪費,不過它也有缺點:
在大量對象存活的情況下,移動對象並更新引用也會花費大量時間
4.4 應用
不同的場景適用不同的垃圾收集算法,像標記-復制算法就適用於存活對象少的情況下,也就是新生代區域,像標記-整理算法就適用於存活對象多的情況下,也就是老年代。
這裡有點需要註意的是,標記-整理算法對於老年代來說也不是完美的,在5.3節我們說過,在大量對象存活的情況下,移動對象和更新引用也是要花費大量時間的,不過算法這個東西吧,它比的是誰更適合,對於標記-復制算法來說,我把區域一分為二,如果大量對象存活,我要把對象全部復制到另一塊內存區域,這個開銷不見得比標記-整理算法少,並且它還有個缺點就是可用內存一下子少瞭一半,這個問題在標記-整理算法中是沒有的。也有的虛擬機采用標記-清除算法與標記-整理算法協作的垃圾收集方案,沒有最適合,隻有更適合。
4.5 優化
前面講標記-復制算法的時候說到要把內存區域等半分,這是在沒有規定場景的情況下,在新生代中采用該垃圾收集算法可以做更好的優化。
眾所周知,新生代中的對象都是朝生夕死的,因此當標記完成後的存活對象肯定是少量的,根據這個現象,可以將內存區域非等半分,比如說9:1的分法,這裡我們將90%的內存區域稱為Eden空間,將10%的內存區域稱為Survivor空間,一開始使用Eden空間的內存,當垃圾收集時,將Eden空間的存活對象復制到Survivor空間中。
這裡肯定有人要問瞭,那下一次使用Survivor空間不是就隻有10%的內存瞭嗎?
對的,所以這裡有兩種解決方案:
- 將存活對象從Eden空間復制到Survivor空間後,再從Survivor空間復制回Eden空間;
- 從Eden空間再分離出一個Survivor空間,每次可使用的內存為一個Eden空間和一個Survivor空間,當垃圾收集時,將使用的內存區域中的存活對象復制到另一個Survivor空間中,下一次的可用內存則為Eden空間和這個Survivor空間,如此循環往復。
第二種方法就是大名鼎鼎的半區復制分代策略,現在叫Appel式回收,因為提出這個策略的人叫Apple,目前很多虛擬機在新生代的垃圾收集算法中采用這個策略。
4.5.1 缺點
半區復制分代策略也是有缺點的,從上面的敘述中我們可以知道,Eden空間和Survivor空間的內存占比為8:1:1,如果當垃圾收集後的存活對象所需要的內存空間大於一個Survivor空間時,那就難辦瞭。
4.5.2 補丁
既然Survivor空間的內存不夠放存活對象瞭,那就去借內存區域,這個借當然不能跟Eden空間和Survivor空間借,不然會影響到整個算法,增加算法的復雜度。新生代不能借,那就跟老年代借,這裡就有一個所謂的內存分配擔保,放不下的存活對象將直接通過分配擔保機制進入到老年代中。有瞭這個“逃生門”一樣的設計,這個策略才算是沒有漏洞。
五、寫在後面
幾個垃圾收集算法的圖是我直接截瞭書裡面的圖,因為我覺得它講的很詳細瞭,第四節垃圾判斷過程在書中實際上是一長串的代碼,看懂不難,不過我想畫個流程圖可能更清楚點,這個流程圖是用plantUML畫出來的,這個工具可以用代碼畫出各種圖,功能強大,有興趣的可以百度搜搜,下面是這個流程圖的代碼:
@startuml
start
:對對象進行可達性分析;
if (對象是否為垃圾?) then (是)
:進行第一次標記;
if (對象沒有覆蓋finalize()方法 或 finalize()方法已經被虛擬機調用) then(是)
:沒必要執行對象的finalize()方法;
else (否)
:將對象放入隊列F-Queue中;
:等待虛擬機的Finalizer線程執行對象的finalize()方法;
:執行對象的finalize()方法;
endif
if (對象是否為垃圾?) then (是)
:進行第二次標記;
:垃圾回收;
else (否)
stop
endif
else (否)
stop
endif
stop
@enduml
到此這篇關於JVM知識總結之垃圾收集算法的文章就介紹到這瞭,更多相關JVM垃圾收集算法內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!