Python趣味爬蟲之爬取愛奇藝熱門電影
一、首先我們要找到目標
找到目標先分析一下網頁很幸運這個隻有一個網頁,不需要翻頁。
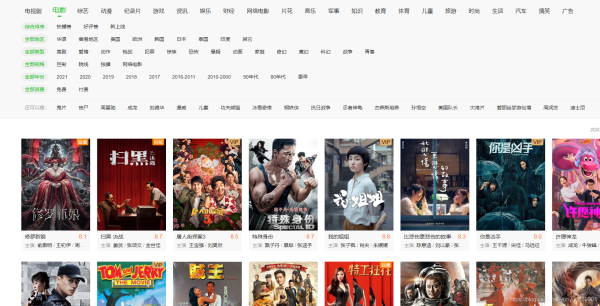
二、F12查看網頁源代碼
找到目標,分析如何獲取需要的數據。找到href與電影名稱
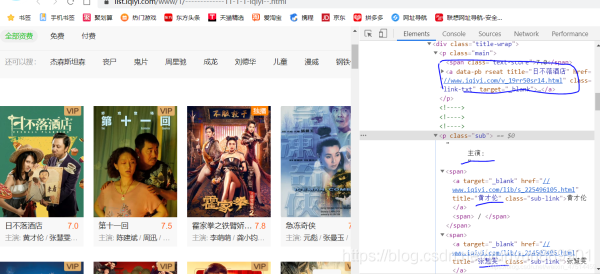
三、進行代碼實現,獲取想要資源。
'''
操作步驟
1,獲取到url內容
2,css選擇其選擇內容
3,保存自己需要數據
'''
#導入爬蟲需要的包
import requests
from bs4 import BeautifulSoup
#requests與BeautifulSoup用來解析網頁的
import time
#設置訪問網頁時間,防止自己IP訪問多瞭被限制拒絕訪問
import re
class Position():
def __init__(self,position_name,position_require,):#構建對象屬性
self.position_name=position_name
self.position_require=position_require
def __str__(self):
return '%s%s/n'%(self.position_name,self.position_require)#重載方法將輸入變量改成字符串形式
class Aiqiyi():
def iqiyi(self,url):
head= {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47"
} #模擬的服務器頭
html = requests.get(url,headers=head)
#headers=hard 讓腳本以瀏覽器的方式去訪問,有一些網址禁止以python的反爬機制,這就是其中一個
soup = BeautifulSoup(html.content, 'lxml', from_encoding='utf-8') # BeautifulSoup打看網頁
soupl = soup.select(".qy-list-wrap") # 查找標簽,用css選擇器,選擇自己需要數據 進行選擇頁面第一次內容(標簽要找到唯一的,找id好,如果沒有考慮其他標簽如class)
results = [] # 創建一個列表用來存儲數據
for e in soupl:
biao = e.select('.qy-mod-li') # 進行二次篩選
for h in biao:
p=Position(h.select_one('.qy-mod-link-wrap').get_text(strip=True),
h.select_one('.title-wrap').get_text(strip=True))#調用類轉換(繼續三次篩選選擇自己需要內容)
results.append(p)
return results # 返回內容
def address(self,url):
#保存網址
head = {
'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47"
} # 模擬的服務器頭
html = requests.get(url, headers=head)
soup = BeautifulSoup(html.content, 'lxml', from_encoding='utf-8') # BeautifulSoup打看網頁
alist = soup.find('div', class_='qy-list-wrap').find_all("a") # 查找div塊模塊下的 a標簽
ls=[]
for i in alist:
ls.append(i.get('href'))
return ls
if __name__ == '__main__':
time.sleep(2)
#設置2秒訪問一次
a=Aiqiyi()
url = "https://list.iqiyi.com/www/1/-------------11-1-1-iqiyi--.html"
with open(file='e:/練習.txt ', mode='a+') as f: # e:/練習.txt 為我電腦新建的文件,a+為給內容進行添加,但不進行覆蓋原內容。
for item in a.iqiyi(url):
line = f'{item.position_name}\t{item.position_require}\n'
f.write(line) # 采用方法
print("下載完成")
with open(file='e:/地址.txt ', mode='a+') as f: # e:/練習.txt 為我電腦新建的文件,a+為給內容進行添加,但不進行覆蓋原內容。
for item in a.address(url):
line=f'https{item}\n'
f.write(line) # 采用方法
print("下載完成")
四、查看現象
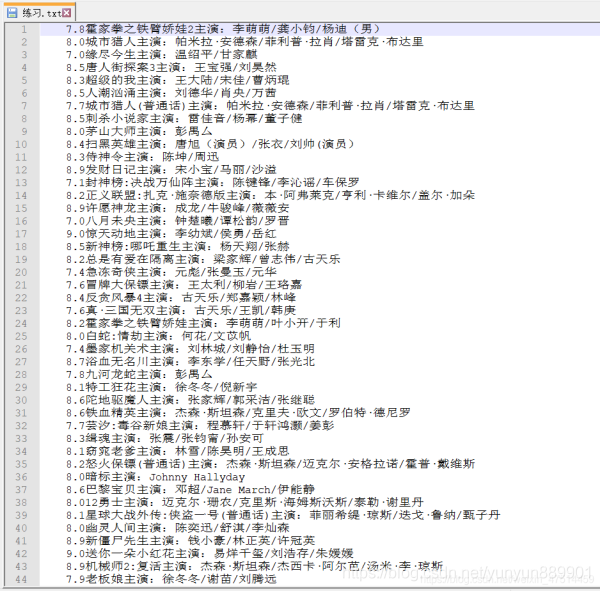
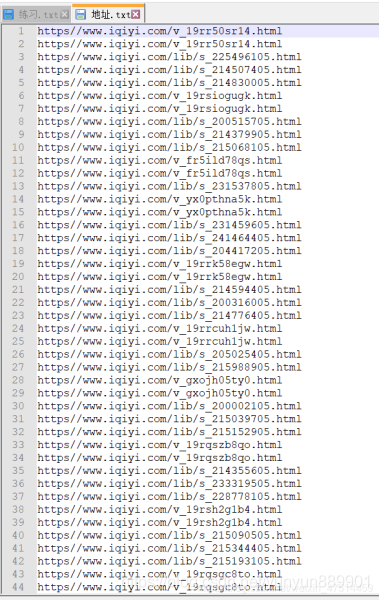
到此這篇關於Python趣味爬蟲之爬取愛奇藝熱門電影的文章就介紹到這瞭,更多相關Python爬取電影內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- 教你怎麼用python爬取愛奇藝熱門電影
- python beautifulsoup4 模塊詳情
- 利用python實現查看溧陽的攝影圈
- Python爬取求職網requests庫和BeautifulSoup庫使用詳解
- python爬蟲學習筆記–BeautifulSoup4庫的使用詳解