Python用requests庫爬取返回為空的解決辦法
首先介紹一下我們用360搜索派取城市排名前20。
我們爬取的網址:https://baike.so.com/doc/24368318-25185095.html
我們要爬取的內容:
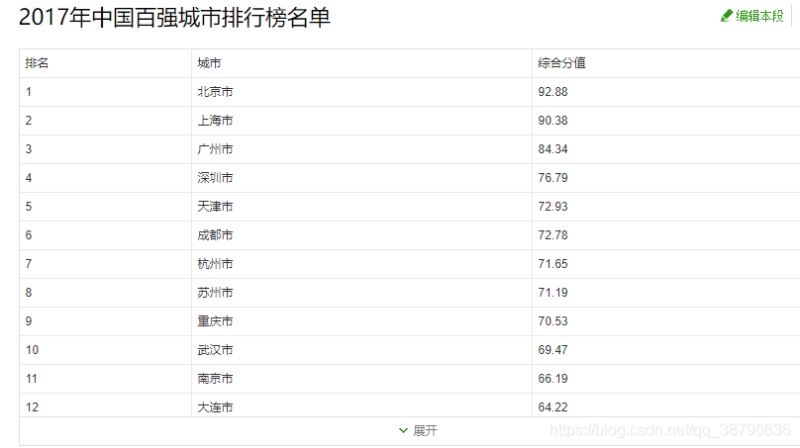
html字段:

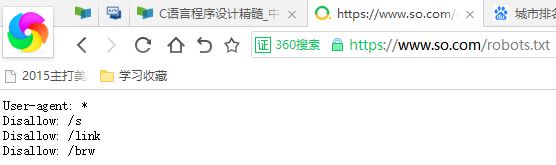
robots協議:
現在我們開始用python IDLE 爬取

import requests
r = requests.get("https://baike.so.com/doc/24368318-25185095.html")
r.status_code
r.text
結果分析,我們可以成功訪問到該網頁,但是得不到網頁的結果。被360搜索識別,我們將headers修改。
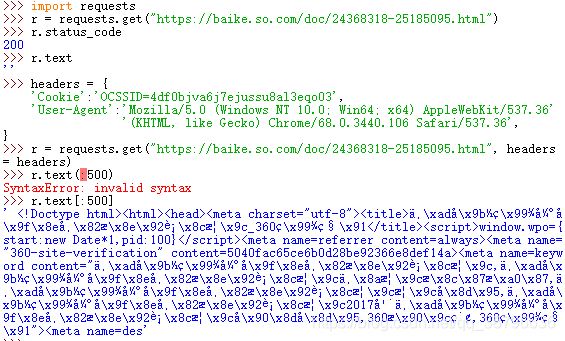
輸出有個小插曲,網頁內容很多,我是想將前500個字符輸出,第一次格式錯瞭
import requests
headers = {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get("https://baike.so.com/doc/24368318-25185095.html", headers = headers)
r.status_code
r.text
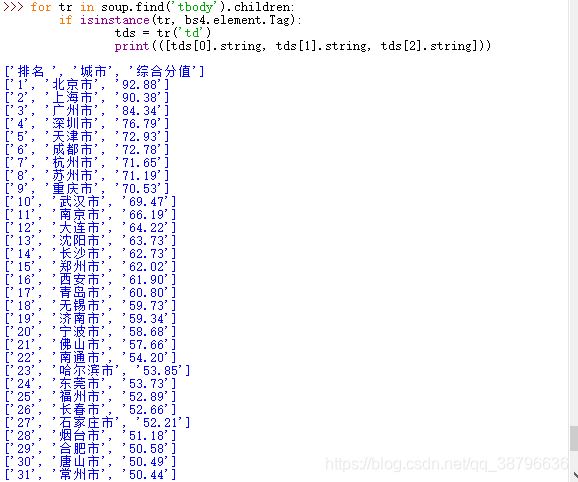
接著我們對需要的內容進行爬取,用(.find)方法找到我們內容位置,用(.children)下行遍歷的方法對內容進行爬取,用(isinstance)方法對內容進行篩選:
import requests
from bs4 import BeautifulSoup
import bs4
headers = {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get("https://baike.so.com/doc/24368318-25185095.html", headers = headers)
r.status_code
r.encoding = r.apparent_encoding
soup = BeautifulSoup(r.text, "html.parser")
for tr in soup.find('tbody').children:
if isinstance(tr, bs4.element.Tag):
tds = tr('td')
print([tds[0].string, tds[1].string, tds[2].string])
得到結果如下:
修改輸出的數目,我們用Clist列表來存取所有城市的排名,將前20個輸出代碼如下:
import requests
from bs4 import BeautifulSoup
import bs4
Clist = list() #存所有城市的列表
headers = {
'Cookie':'OCSSID=4df0bjva6j7ejussu8al3eqo03',
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
'(KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
r = requests.get("https://baike.so.com/doc/24368318-25185095.html", headers = headers)
r.encoding = r.apparent_encoding #將html的編碼解碼為utf-8格式
soup = BeautifulSoup(r.text, "html.parser") #重新排版
for tr in soup.find('tbody').children: #將tbody標簽的子列全部讀取
if isinstance(tr, bs4.element.Tag): #篩選tb列表,將有內容的篩選出啦
tds = tr('td')
Clist.append([tds[0].string, tds[1].string, tds[2].string])
for i in range(21):
print(Clist[i])
最終結果:
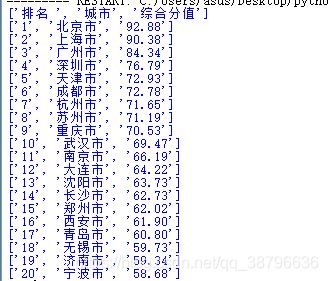
到此這篇關於Python用requests庫爬取返回為空的解決辦法的文章就介紹到這瞭,更多相關Python requests返回為空內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python爬取求職網requests庫和BeautifulSoup庫使用詳解
- 基於pycharm的beautifulsoup4庫使用方法教程
- Python爬蟲爬取網站圖片
- Python趣味爬蟲之爬取愛奇藝熱門電影
- 教你怎麼用python爬取愛奇藝熱門電影