python爬取分析超級大樂透歷史開獎數據第1/2頁
博主作為爬蟲初學者,本次使用瞭requests和beautifulsoup庫進行數據的爬取
爬取網站:http://datachart.500.com/dlt/history/history.shtml —500彩票網
(分析後發現網站源代碼並非是通過頁面跳轉來查找不同的數據,故可通過F12查找network欄找到真正儲存所有歷史開獎結果的網頁)
如圖:
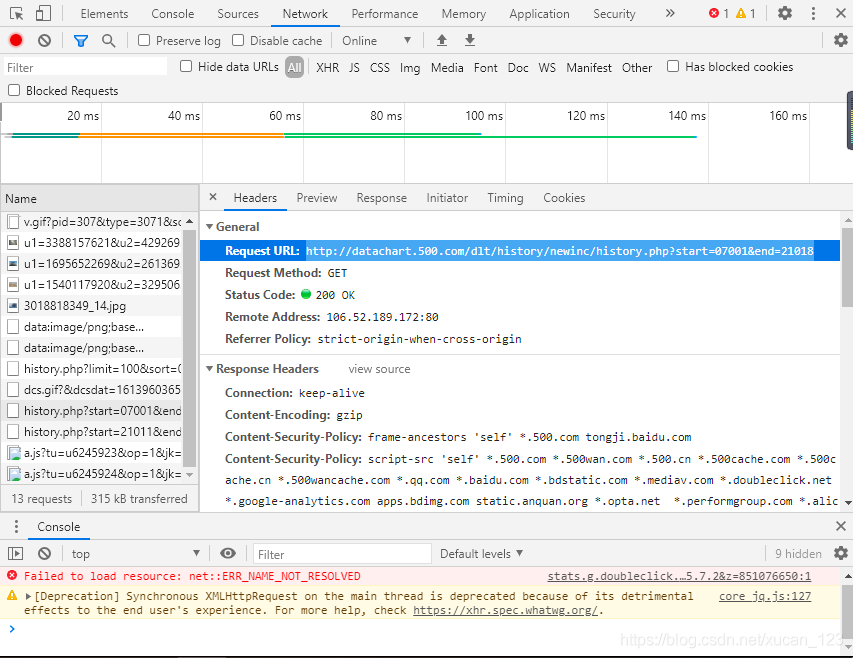
爬蟲部分:
from bs4 import BeautifulSoup #引用BeautifulSoup庫
import requests #引用requests
import os #os
import pandas as pd
import csv
import codecslst=[]
url='http://datachart.500.com/dlt/history/newinc/history.php?start=07001&end=21018'
r = requests.get(url)
r.encoding='utf-8'
text=r.text
soup = BeautifulSoup(text, "html.parser")
tbody=soup.find('tbody',id="tdata")
tr=tbody.find_all('tr')
td=tr[0].find_all('td')
for page in range(0,14016):
td=tr12下一頁閱讀全文推薦閱讀:
- Python使用Beautiful Soup實現解析網頁
- Python用requests庫爬取返回為空的解決辦法
- 基於pycharm的beautifulsoup4庫使用方法教程
- Python爬取求職網requests庫和BeautifulSoup庫使用詳解
- python爬蟲beautifulsoup庫使用操作教程全解(python爬蟲基礎入門)