Python爬取網站圖片並保存的實現示例
先看看結果吧,去bilibili上拿到的圖片=-=
第一步,導入模塊
import requests from bs4 import BeautifulSoup
requests用來請求html頁面,BeautifulSoup用來解析html
第二步,獲取目標html頁面
hd = {'user-agent': 'chrome/10'} # 偽裝自己是個(chrome)瀏覽器=-=
def download_all_html():
try:
url = 'https://www.bilibili.com/' # 將要爬取網站的地址
request = requests.get(url, timeout=30, headers=hd) # 獲取改網站的信息
request.raise_for_status() # 判斷狀態碼是否為200,!=200顯然爬取失敗
request.encoding = request.apparent_encoding # 設置編碼格式
return request.text # 返回html頁面
except:
return ''
第三步,分析網站html構造
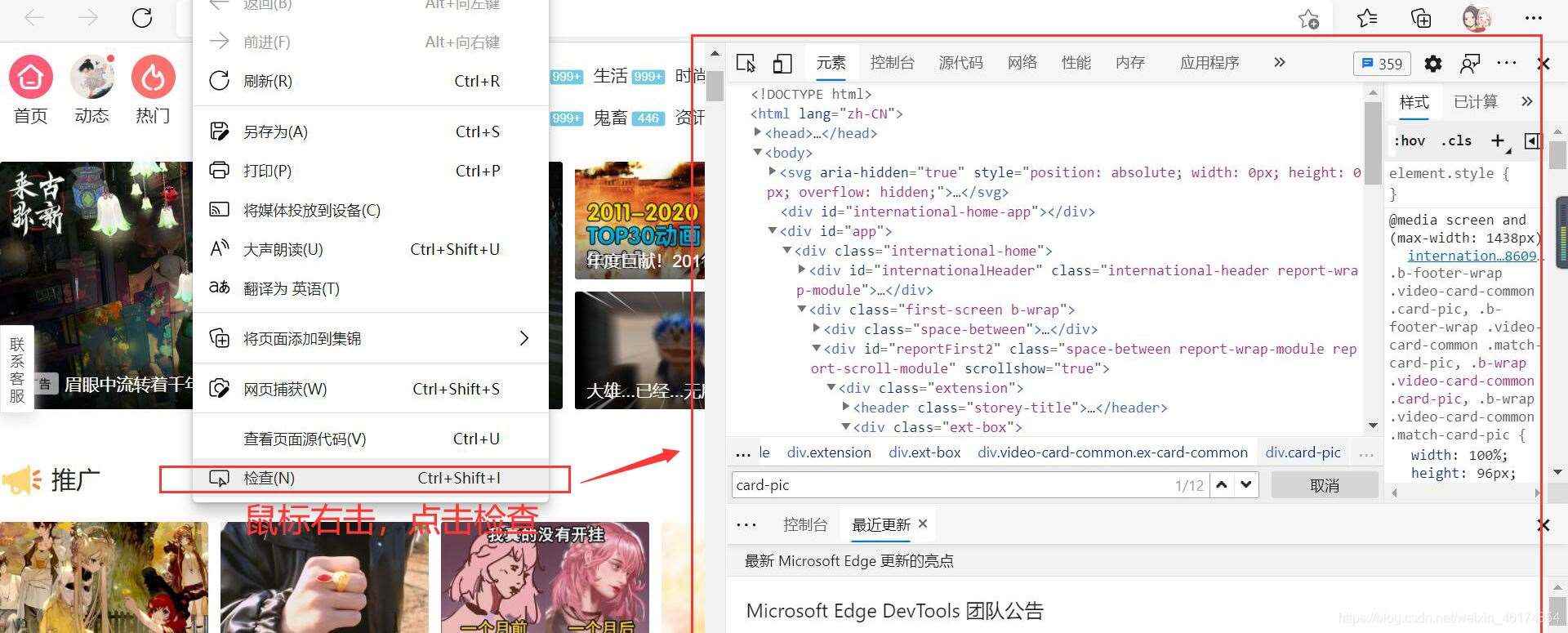
1、顯示網站html代碼
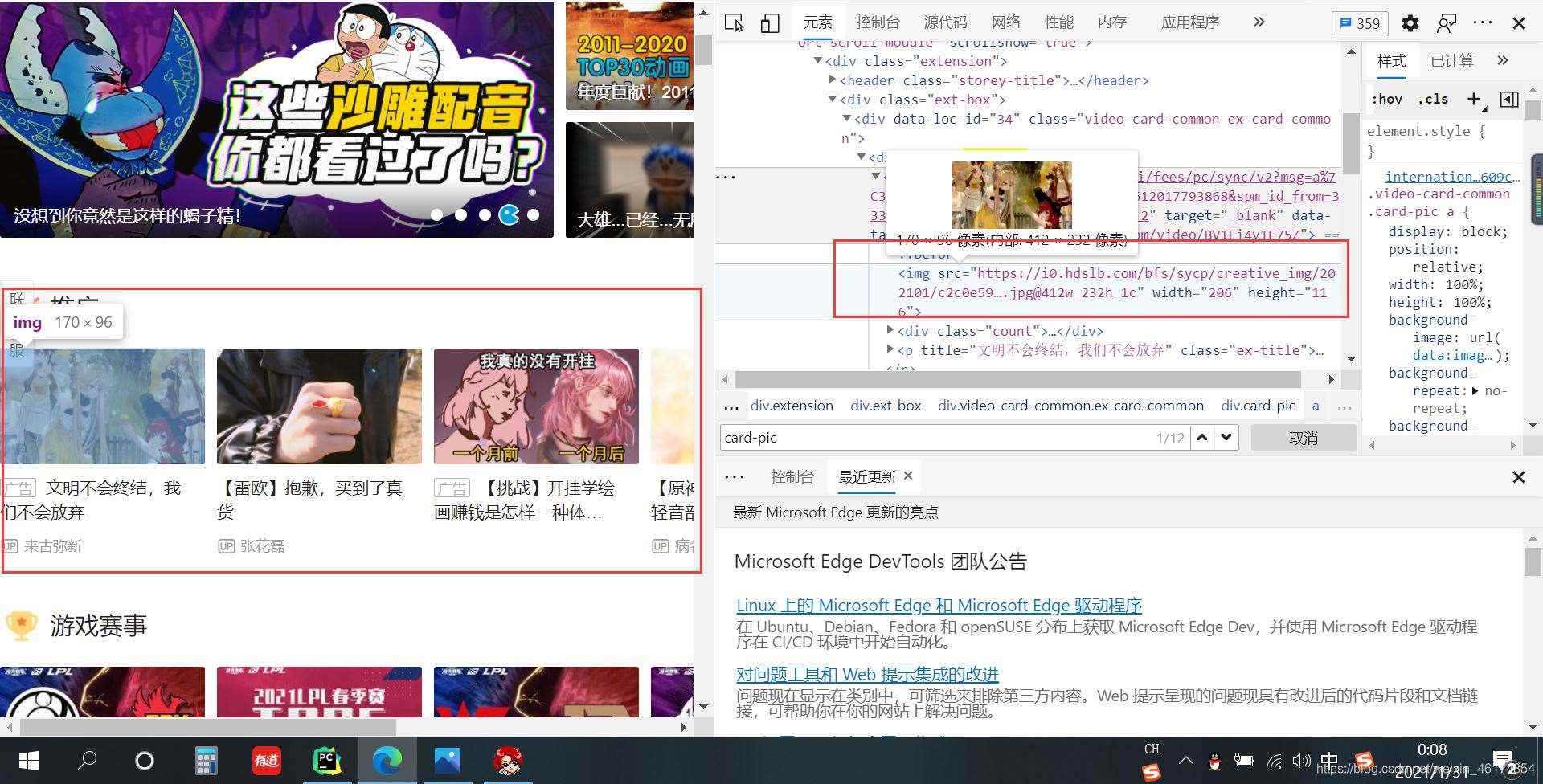
2、找到圖片位置
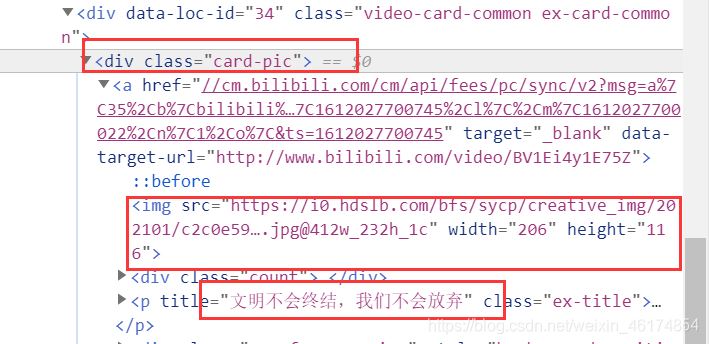
3、分析

第四步,直接上代碼註釋夠詳細=-=
def parse_single_html(html):
soup = BeautifulSoup(html, 'html.parser') # 解析html,可以單獨去瞭解一下他的使用
divs = soup.find_all('div', class_='card-pic') # 獲取滿足條件的div,find_all(所有)
for div in divs: # 瞞住條件的div有多個,我們單獨獲取
p = div.find('p') # 有源代碼可知,每個div下都有一個p標簽,存儲圖片的title,獲取p標簽
if p == None:
continue
title = p['title'] # 獲取p標簽中的title屬性,用來做圖片的名稱
img = div.find('img')['src'] # 獲取圖片的地址
if img[0:6] != 'https:': # 根據源代碼發現,有的地址缺少"https:"前綴
img = 'https:' + img # 如果缺少,我們給他添上就行啦,都據情況而定
response = requests.get(img) # get方法得到圖片地址(有的是post、put)基本是get
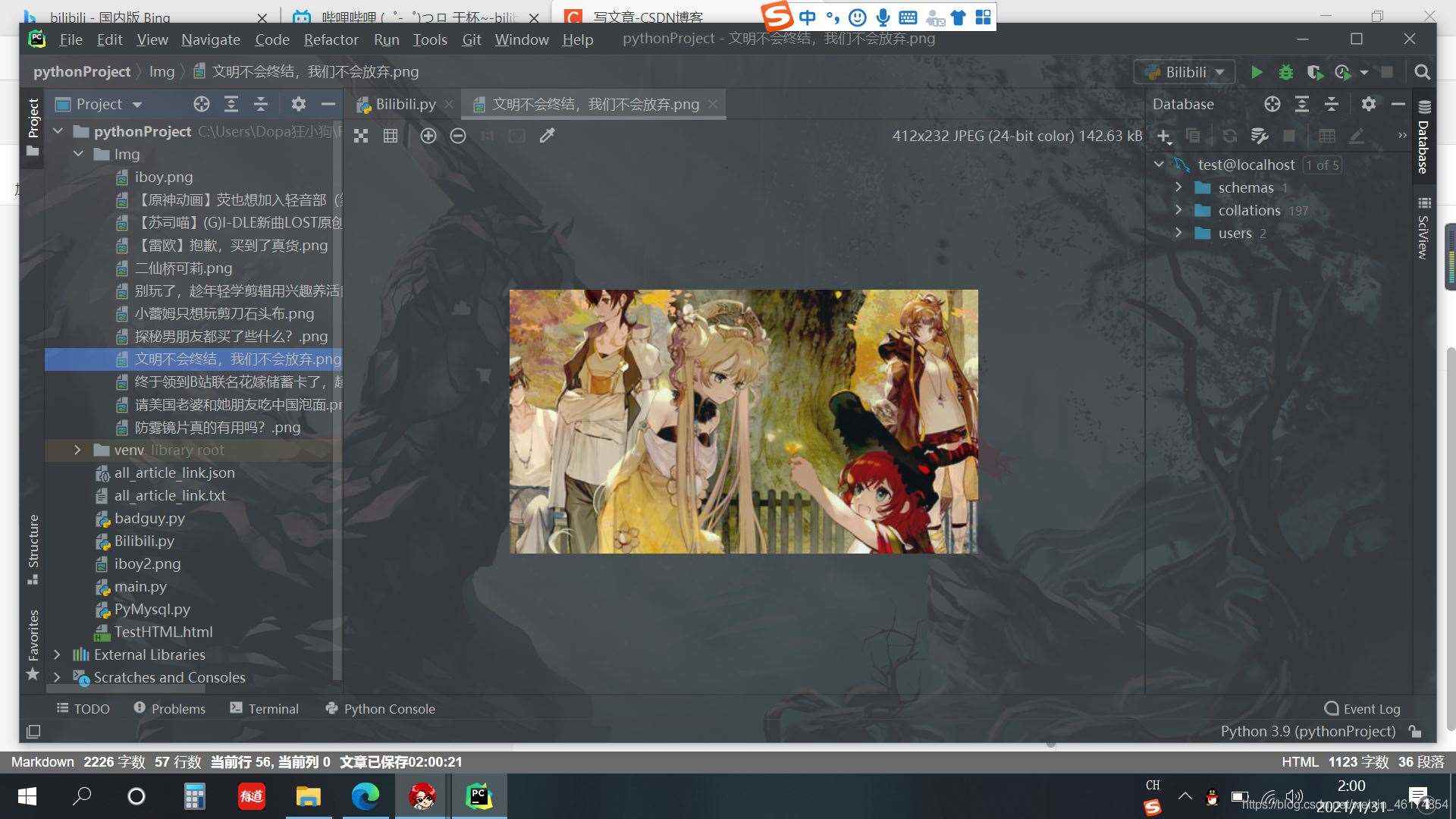
with open('./Img/{}.png'.format(title), 'wb') as f: # 創建用來保存圖片的.png文件
f.write(response.content) # 註意,'wb'中的b 必不可少!!
parse_single_html(download_all_html()) # 最後調用我們寫的兩個函數就行啦,
查看結果
到此這篇關於Python爬取網站圖片並保存的實現示例的文章就介紹到這瞭,更多相關Python爬取圖片保存內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Python使用Beautiful Soup實現解析網頁
- 使用Python爬取小姐姐圖片(beautifulsoup法)
- python爬蟲爬取bilibili網頁基本內容
- 基於pycharm的beautifulsoup4庫使用方法教程
- Python爬蟲網頁元素定位術