Python Django 數據庫的相關操作詳解
前言
上篇已經介紹過模型相關操作,並創建好瞭數據庫及相關表字段,接下來將通過以下表在Django中進行表數據的增改查。
from django.db import models
class Student(models.Model):
"""
學生表
"""
name = models.CharField('學生姓名', max_length=200, unique=True, help_text='學生姓名')
gender = models.SmallIntegerField('性別', default='1', help_text='性別')
hobby = models.CharField('愛好', max_length=200, null=True, blank=True, help_text='興趣愛好')
create_time = models.DateTimeField('創建時間', auto_now_add=True, help_text='創建時間')
class Meta:
"""
元數據,
"""
db_table = 'student' # 指定當前模型創建的表明,不寫默認當前的模型名Student
verbose_name = '學生信息表' # 註釋
verbose_name_plural = verbose_name # 指定為復數
ordering = ['-create_time'] # 使用創建時間倒序排序,不加-為正序
def __str__(self):
return self.name # 方便於調式,下面操作數據庫時會體現出來

為瞭更方便調試,接下來通過控制臺輸出的形式進行相關操作,通過python manage.py shell命令會導入當前項目的django環境,在此前需要配置下日志輸出的相關信息,將以下配置在settings.py文件中:
# 日志配置
LOGGING = {
'version': 1,
'handlers': {
'console': {
'class': 'logging.StreamHandler'
}
},
'loggers': {
'django': {
'handlers': ['console'],
'level': 'DEBUG',
'propagate': False
}
}
}
創建對象
前面介紹過一個模型類代表一張表,而類的實例則代表表中的一條記錄,所以可以通過實例化模型類的形式來進行表記錄創建,如下:
方式一:
實例化時創建傳入字段,然後通過save方法保存
# 導入模型類
In [1]: from project2s.models import Student
# 實例化對象,傳入必傳字段
In [2]: s = Student(name='test',hobby='打籃球')
# 調用save方法保存到數據庫,
In [3]: s.save()
# 輸出內容如下:其底層還是使用的INSERT語句
(0.031) INSERT INTO `student` (`name`, `gender`, `hobby`, `create_time`) VALUES ('test', 1, '打籃球', '2021-11-10 12:49:13.814987') RETURNING `student`.`id`; args=('test', 1, '打籃球',
'2021-11-10 12:49:13.814987')
數據庫插入成功:

方式二:
先實例化然後通過給屬性賦值的形式,在通過save方法保存
In [2]: s1 = Student()
In [3]: s1.name = 'test1'
In [4]: s1.hobby = '唱歌'
In [5]: s1.save()
(0.031) INSERT INTO `student` (`name`, `gender`, `hobby`, `create_time`) VALUES ('test1', 1, '唱歌', '2021-11-10 13:13:41.183826') RETURNING `student`.`id`; args=('test1', 1, '唱歌', '
2021-11-10 13:13:41.183826')
數據庫插入成功:

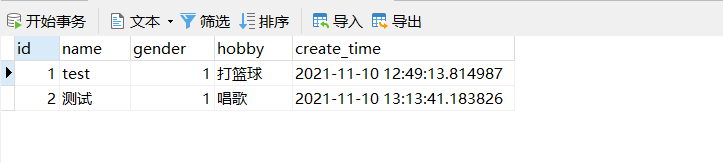
更新對象
更新時會檢索對象的id是否存在,存在即修改。
修改實例屬性,並通過save方法保存到數據庫,底層使用UPDATE語句
方式一:
In [6]: s1.name = '測試'
In [7]: s1.save()
(0.031) UPDATE `student` SET `name` = '測試', `gender` = 1, `hobby` = '唱歌', `create_time` = '2021-11-10 13:13:41.183826' WHERE `student`.`id` = 2; args=('測試', 1, '唱歌', '2021-11-1
0 13:13:41.183826', 2)
數據庫更新成功:
但隻是修改瞭一個字段,可見UPDATE語句執行時修改瞭全部字段會造成性能問題,可以通過以下方式指定字段更新。
方式二:
save時通過update_fields指定字段
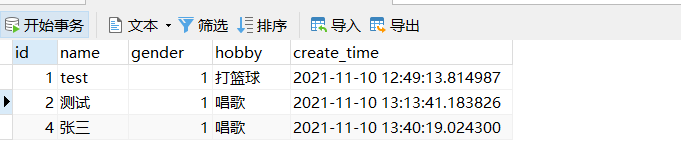
# 前面已經實例化過s2=Student(name='張三',hobby='唱歌')
In [11]: s2.name = '李四'
In [12]: s2.save(update_fields=['name'])
(0.047) UPDATE `student` SET `name` = '李四' WHERE `student`.`id` = 4; args=('李四', 4)
數據庫更新成功:

方式三:
批量修改,通過模型類管理器objects,查詢到所有記錄,在調用update方法
In [2]: Student.objects.all().update(hobby='玩遊戲')
(0.031) UPDATE `student` SET `hobby` = '玩遊戲'; args=('玩遊戲',)
Out[2]: 3
數據庫更新成功:

查詢
查詢使用模型類的管理器objects,前面批量更改時已經用到過,當通過管理器查詢,會生成一個QuerySet對象,代表瞭數據庫中對象的集合,它可以迭代,支持切片,不支持負索引,還可以用list轉換成列表。在sql的層面上個代表瞭select語句。
檢索全部對象:
Stutent.objects.all() 得到的是QuerySet對象,模型類中定義瞭__ str __方法,輸出瞭name。
In [4]: Student.objects.all() Out[4]: (0.094) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`create_time` DESC LIMIT 21; a rgs=() <QuerySet [<Student: 李四>, <Student: 測試>, <Student: test>]> # 轉換成列表 In [5]: list(Student.objects.all()) (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`create_time` DESC; args=() Out[5]: [<Student: 李四>, <Student: 測試>, <Student: test>] # 通過索引 In [6]: Student.objects.all()[0] (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`create_time` DESC LIMIT 1; args=() Out[6]: <Student: 李四> # 通過切片 In [5]: Student.objects.all()[:2] # 等價於 LIMIT 2 Out[5]: (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`create_time` DESC LIMIT 2; ar gs=() <QuerySet [<Student: 李四>, <Student: 測試>]> In [4]: Student.objects.all()[1:2] # 等價於 LIMIT 1 OFF SET 1 Out[4]: (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`create_time` DESC LIMIT 1 OFF SET 1; args=() <QuerySet [<Student: 測試>]>
條件過濾:
方式一:
filter(**kwargs),包含滿足給定查詢參數的對象
In [4]: Student.objects.all().filter(name='李四')
Out[4]: (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` WHERE `student`.`name` = '李四' ORDER BY `student
`.`create_time` DESC LIMIT 21; args=('李四',)
<QuerySet [<Student: 李四>]>
方式二:
exclude(**kwargs) ,不包含滿足給定查詢參數的對象
In [4]: Student.objects.all().exclude(name='李四')
Out[4]: (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` WHERE NOT (`student`.`name` = '李四') ORDER BY `s
tudent`.`create_time` DESC LIMIT 21; args=('李四',)
<QuerySet [<Student: 測試>, <Student: test>]>
檢索單個對象:
通過get方法如果檢索超過1條數據會報錯,所以一般配合pk使用
In [4]: Student.objects.all().get(pk=1) (0.047) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` WHERE `student`.`id` = 1 LIMIT 21; args=(1,) Out[4]: <Student: test>
返回第一條數據:
Stutent.objects.all().first()
In [5]: Student.objects.all().first() (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`create_time` DESC LIMIT 1; args=() Out[5]: <Student: 李四>
返回最後一條數據:
Stutent.objects.all().last()
In [6]: Student.objects.all().last() (0.031) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`create_time` ASC LIMIT 1; args=() Out[6]: <Student: test>
由於模型類Meta內設置瞭通過時間倒序排序,所以查詢結果會相反。
排序:
order_by(*fields),根據給定的字段進行排序。默認按照模型類中的Meta類來排序。
正序:
In [3]: Student.objects.all().order_by('name')
Out[3]: (0.047) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`name` ASC LIMIT 21; args=()
<QuerySet [<Student: test>, <Student: 李四>, <Student: 測試>]>
倒序:
In [4]: Student.objects.all().order_by('-name')
Out[4]: (0.047) SELECT `student`.`id`, `student`.`name`, `student`.`gender`, `student`.`hobby`, `student`.`create_time` FROM `student` ORDER BY `student`.`name` DESC LIMIT 21; args=()
<QuerySet [<Student: 測試>, <Student: 李四>, <Student: test>]>
總結
本篇文章就到這裡瞭,希望能夠給你帶來幫助,也希望您能夠多多關註WalkonNet的更多內容!
推薦閱讀:
- django中操作mysql數據庫的方法
- django中F與Q查詢的使用
- django模型查詢操作的實現
- 詳解python中mongoengine庫用法
- 使用Django框架中ORM系統實現對數據庫數據增刪改查