python中k-means和k-means++原理及實現
前言
k-means算法是無監督的聚類算法,實現起來較為簡單,k-means++可以理解為k-means的增強版,在初始化中心點的方式上比k-means更友好。
k-means原理
k-means的實現步驟如下:
- 從樣本中隨機選取k個點作為聚類中心點
- 對於任意一個樣本點,求其到k個聚類中心的距離,然後,將樣本點歸類到距離最小的聚類中心,直到歸類完所有的樣本點(聚成k類)
- 對每個聚類求平均值,然後將k個均值分別作為各自聚類新的中心點
- 重復2、3步,直到中心點位置不在變化或者中心點的位置變化小於閾值
優點:
- 原理簡單,實現起來比較容易
- 收斂速度較快,聚類效果較優
缺點:
- 初始中心點的選取具有隨機性,可能會選取到不好的初始值。
k-means++原理
k-means++是k-means的增強版,它初始選取的聚類中心點盡可能的分散開來,這樣可以有效減少迭代次數,加快運算速度,實現步驟如下:
- 從樣本中隨機選取一個點作為聚類中心
- 計算每一個樣本點到已選擇的聚類中心的距離,用D(X)表示:D(X)越大,其被選取下一個聚類中心的概率就越大
- 利用輪盤法的方式選出下一個聚類中心(D(X)越大,被選取聚類中心的概率就越大)
- 重復步驟2,直到選出k個聚類中心
- 選出k個聚類中心後,使用標準的k-means算法聚類
這裡不得不說明一點,有的文獻中把與已選擇的聚類中心最大距離的點選作下一個中心點,這個說法是不太準確的,準的說是與已選擇的聚類中心最大距離的點被選作下一個中心點的概率最大,但不一定就是改點,因為總是取最大也不太好(遇到特殊數據,比如有一個點離某個聚類所有點都很遠)。
一般初始化部分,始終要給些隨機。因為數據是隨機的。
盡管計算初始點時花費瞭額外的時間,但是在迭代過程中,k-mean 本身能快速收斂,因此算法實際上降低瞭計算時間。
現在重點是利用輪盤法的方式選出下一個聚類中心,我們以一個例子說明K-means++是如何選取初始聚類中心的。
假如數據集中有8個樣本,分佈分佈以及對應序號如下圖所示:
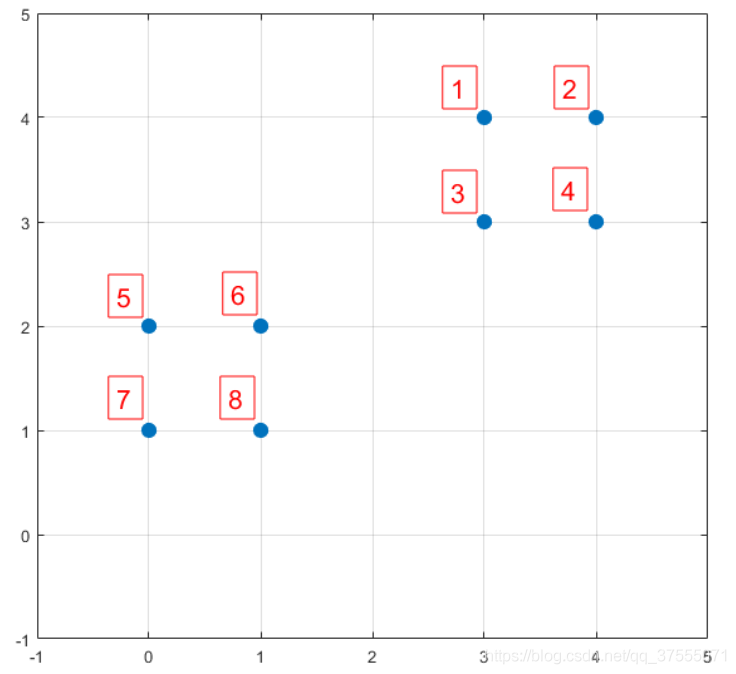
我們先用 k-means++的步驟1選擇6號點作為第一個聚類中心,然後進行第二步,計算每個樣本點到已選擇的聚類中心的距離D(X),如下所示:
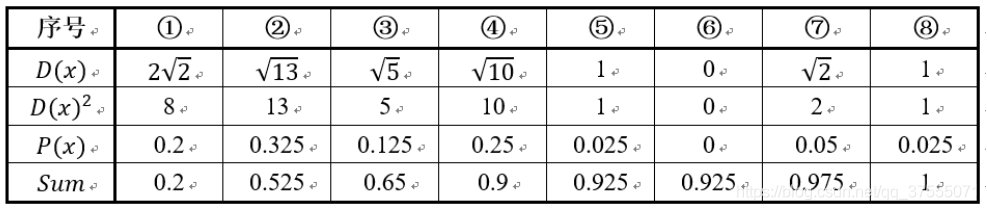
- D(X)是每個樣本點與所選取的聚類中心的距離(即第一個聚類中心)
- P(X)每個樣本被選為下一個聚類中心的概率
- Sum是概率P(x)的累加和,用於輪盤法選擇出第二個聚類中心。
然後執行 k-means++的第三步:利用輪盤法的方式選出下一個聚類中心,方法是隨機產生出一個0~1之間的隨機數,判斷它屬於哪個區間,那麼該區間對應的序號就是被選擇出來的第二個聚類中心瞭。
在上圖1號點區間為[0,0.2),2號點的區間為[0.2, 0.525),4號點的區間為[0.65,0.9)
從上表可以直觀的看到,1號,2號,3號,4號總的概率之和為0.9,這4個點正好是離第一個初始聚類中心(即6號點)較遠的四個點,因此選取的第二個聚類中心大概率會落在這4個點中的一個,其中2號點被選作為下一個聚類中心的概率最大。
k-means及k-means++代碼實現
這裡選擇的中心點是樣本的特征(不是索引),這樣做是為瞭方便計算,選擇的聚類點(中心點周圍的點)是樣本的索引。
k-means實現
# 定義歐式距離
import numpy as np
def get_distance(x1, x2):
return np.sqrt(np.sum(np.square(x1-x2)))
import random
# 定義中心初始化函數,中心點選擇的是樣本特征
def center_init(k, X):
n_samples, n_features = X.shape
centers = np.zeros((k, n_features))
selected_centers_index = []
for i in range(k):
# 每一次循環隨機選擇一個類別中心,判斷不讓centers重復
sel_index = random.choice(list(set(range(n_samples))-set(selected_centers_index)))
centers[i] = X[sel_index]
selected_centers_index.append(sel_index)
return centers
# 判斷一個樣本點離哪個中心點近, 返回的是該中心點的索引
## 比如有三個中心點,返回的是0,1,2
def closest_center(sample, centers):
closest_i = 0
closest_dist = float('inf')
for i, c in enumerate(centers):
# 根據歐式距離判斷,選擇最小距離的中心點所屬類別
distance = get_distance(sample, c)
if distance < closest_dist:
closest_i = i
closest_dist = distance
return closest_i
# 定義構建聚類的過程
# 每一個聚類存的內容是樣本的索引,即對樣本索引進行聚類,方便操作
def create_clusters(centers, k, X):
clusters = [[] for _ in range(k)]
for sample_i, sample in enumerate(X):
# 將樣本劃分到最近的類別區域
center_i = closest_center(sample, centers)
# 存放樣本的索引
clusters[center_i].append(sample_i)
return clusters
# 根據上一步聚類結果計算新的中心點
def calculate_new_centers(clusters, k, X):
n_samples, n_features = X.shape
centers = np.zeros((k, n_features))
# 以當前每個類樣本的均值為新的中心點
for i, cluster in enumerate(clusters): # cluster為分類後每一類的索引
new_center = np.mean(X[cluster], axis=0) # 按列求平均值
centers[i] = new_center
return centers
# 獲取每個樣本所屬的聚類類別
def get_cluster_labels(clusters, X):
y_pred = np.zeros(np.shape(X)[0])
for cluster_i, cluster in enumerate(clusters):
for sample_i in cluster:
y_pred[sample_i] = cluster_i
#print('把樣本{}歸到{}類'.format(sample_i,cluster_i))
return y_pred
# 根據上述各流程定義kmeans算法流程
def Mykmeans(X, k, max_iterations,init):
# 1.初始化中心點
if init == 'kmeans':
centers = center_init(k, X)
else: centers = get_kmeansplus_centers(k, X)
# 遍歷迭代求解
for _ in range(max_iterations):
# 2.根據當前中心點進行聚類
clusters = create_clusters(centers, k, X)
# 保存當前中心點
pre_centers = centers
# 3.根據聚類結果計算新的中心點
new_centers = calculate_new_centers(clusters, k, X)
# 4.設定收斂條件為中心點是否發生變化
diff = new_centers - pre_centers
# 說明中心點沒有變化,停止更新
if diff.sum() == 0:
break
# 返回最終的聚類標簽
return get_cluster_labels(clusters, X)
# 測試執行
X = np.array([[0,2],[0,0],[1,0],[5,0],[5,2]])
# 設定聚類類別為2個,最大迭代次數為10次
labels = Mykmeans(X, k = 2, max_iterations = 10,init = 'kmeans')
# 打印每個樣本所屬的類別標簽
print("最後分類結果",labels)
## 輸出為 [1. 1. 1. 0. 0.]
# 使用sklearn驗證 from sklearn.cluster import KMeans X = np.array([[0,2],[0,0],[1,0],[5,0],[5,2]]) kmeans = KMeans(n_clusters=2,init = 'random').fit(X) # 由於center的隨機性,結果可能不一樣 print(kmeans.labels_)
k-means++實現
## 得到kmean++中心點
def get_kmeansplus_centers(k, X):
n_samples, n_features = X.shape
init_one_center_i = np.random.choice(range(n_samples))
centers = []
centers.append(X[init_one_center_i])
dists = [ 0 for _ in range(n_samples)]
# 執行
for _ in range(k-1):
total = 0
for sample_i,sample in enumerate(X):
# 得到最短距離
closet_i = closest_center(sample,centers)
d = get_distance(X[closet_i],sample)
dists[sample_i] = d
total += d
total = total * np.random.random()
for sample_i,d in enumerate(dists): # 輪盤法選出下一個聚類中心
total -= d
if total > 0:
continue
# 選取新的中心點
centers.append(X[sample_i])
break
return centers
X = np.array([[0,2],[0,0],[1,0],[5,0],[5,2]])
# 設定聚類類別為2個,最大迭代次數為10次
labels = Mykmeans(X, k = 2, max_iterations = 10,init = 'kmeans++')
print("最後分類結果",labels)
## 輸出為 [1. 1. 1. 0. 0.]
# 使用sklearn驗證 X = np.array([[0,2],[0,0],[1,0],[5,0],[5,2]]) kmeans = KMeans(n_clusters=2,init='k-means++').fit(X) print(kmeans.labels_)
參考文檔
K-means與K-means++
K-means原理、優化及應用
到此這篇關於python中k-means和k-means++原理及實現的文章就介紹到這瞭,更多相關python k-means和k-means++ 內容請搜索LevelAH以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持LevelAH!
推薦閱讀:
- 人工智能——K-Means聚類算法及Python實現
- python中K-means算法基礎知識點
- Python sklearn中的K-Means聚類使用方法淺析
- Python實現聚類K-means算法詳解
- python 基於空間相似度的K-means軌跡聚類的實現