ElasticSearch核心概念
簡介
Elasticsearch 是一個分佈式可擴展的實時搜索和分析引擎,一個建立在全文搜索引擎 Apache Lucene™ 基礎上的搜索引擎.當然 Elasticsearch 並不僅僅是 Lucene 那麼簡單,它不僅包括瞭全文搜索功能,還可以進行以下工作:
- 分佈式實時文件存儲,並將每一個字段都編入索引,使其可以被搜索。
- 實時分析的分佈式搜索引擎。
- 可以擴展到上百臺服務器,處理PB級別的結構化或非結構化數據。
核心概念
以下為ES和Mysql等的對照關系
| Relational DB | Elasticsearch |
|---|---|
| 數據庫(database) | 索引(indices) |
| 表(tables) | types |
| 行(rows) | documents |
| 字段(columns) | fields |
文檔
就是類似關系型數據庫的一行行的記錄
elasticsearch是面向文檔的,那麼就意味著索弓和搜索數據的最小單位是文檔。
elasticsearch中,文檔有幾個重要屬性:
- 自我包含, 一篇文檔同時包含字段和對應的值,也就是同時包含key:value !
- 可以是層次型的
- 靈活的結構,文檔不依賴預先定義的模式,我們知道關系型數據庫中,要提前定義字段才能使用,在elasticsearch中,對於字段是非常靈活的,有時候,我們可以忽略該字段,或者動態的添加一個新的字段。
盡管我們可以隨意的新增或者忽略某個字段,但是,每個字段的類型非常重要,比如一一個年齡字段類型,可以是字符串也可以是整形。因為elasticsearch會保存字段和類型之間的映射及其他的設置。這種映射具體到每個映射的每種類型,這也是為什麼在elasticsearch中,類型有時候也稱為映射類型。
類型
ES7之後Type被舍棄
類型是文檔的邏輯容器,就像關系型數據庫中的表一樣。
類型中對於字段的定義稱為映射,比如name映射為字符串類型。
我們說文檔是無模式的 ,它們不需要擁有映射中所定義的所有字段。
但是如果要新增一個字段,那麼elasticsearch的流程是什麼?
elasticsearch會自動的將新字段加入映射,但是這個字段的不確定它是什麼類型, elasticsearch就開始猜,如果這個值是18 ,那麼elasticsearch會認為它是整形。但是elasticsearch也可能猜不對 ,所以最安全的方式就是提前定義好所需要的映射,這點跟關系型數據庫殊途同歸瞭,先定義好字段,然後再使用。
索引
可以淺顯的理解為就是數據庫。
索引是映射類型的容器, elasticsearch中的索引是一個非常大的文檔集合。索引存儲瞭映射類型的字段和其他設置。然後它們被存儲到瞭各個分片上。
節點
Node為集群中的單臺節點,其可以為master節點亦可為slave節點(節點屬性由集群內部選舉得出)並提供存儲相關數據的功能
分片
在es中,默認一個Es就是一個集群,一個集群又至少有一個節點。而一個節點就是一個es進程,節點可以有多個默認索引,如果你創建新索引,那麼索引將會由5個分片( primary shard ,又稱主分片)構成,每一個主分片會有一個副本( replica shard ,又稱復制分片)
分片有兩種類型:primary主片和replica副本,primary用於文檔存儲,Replica shard是Primary Shard的副本,用於冗餘數據及提高搜索性能。

上圖是一個有3個節點的集群,可以看到主分片和對應的復制分片都不會在同一個節點內,這樣有利於某個節點掛掉瞭,數據也不至於丟失。
實際上, 一個分片是一個Lucene索引, 一個包含倒排索引的文件目錄,倒排索引的結構使得elasticsearch在不掃描全部文檔的情況下,就能告訴你哪些文檔包含特定的關鍵字
倒排索引
elasticsearch使用的是一種稱為倒排索引的結構,采用Lucene倒排索作為底層。這種結構適用於快速的全文搜索,一個索引由文檔中所有不重復的列表構成,對於每一個詞,都有一個包含它的文檔列表。 例如,現在有兩個文檔,每個文檔包含如下內容:
Study every day, good good up to forever # 文檔1包含的內容 To forever, study every day,good good up # 文檔2包含的內容
為為創建倒排索引,我們首先要將每個文檔拆分成獨立的詞(或稱為詞條或者tokens) ,然後創建一個包含所有不重復的詞條的排序列表,然後列出每個詞條出現在哪個文檔:
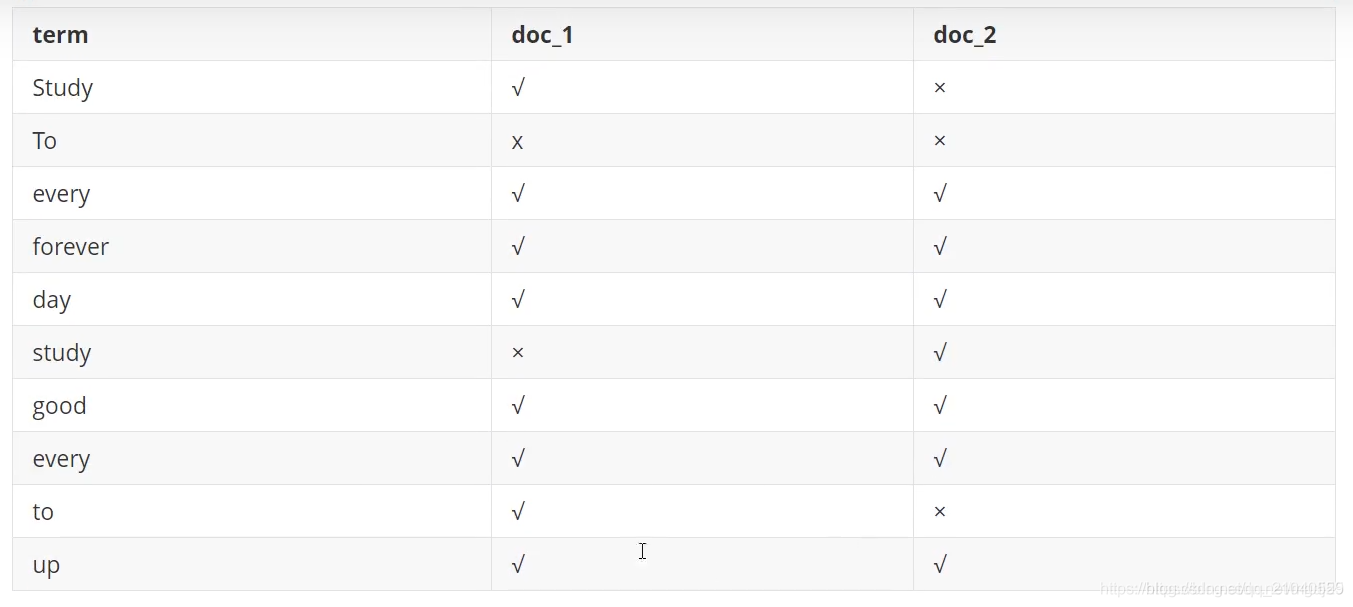
現在,我們試圖搜索 to forever,隻需要查看包含每個詞條的文檔

兩個文檔都匹配,但是第一個文檔比第二個匹配程度更高。如果沒有別的條件,現在,這兩個包含關鍵字的文檔都將返回。
再來看一個示例,比如我們通過博客標簽來搜索博客文章。那麼倒排索引列表就是這樣的一個結構:
| 博客文章(原始數據) | 博客文章(原始數據) | 索引列表(倒排索引) | 索引列表(倒排索引) |
|---|---|---|---|
| 博客文章ID | 標簽 | 標簽 | 博客文章ID |
| 1 | python | python | 1,2,3 |
| 2 | python | linux | 3,4 |
| 3 | linux,python | ||
| 4 | linux |
如果要搜索含有python標簽的文章,那相對於查找所有原始數據而言,查找倒排索引後的數據將會快的多。隻需要查看標簽這一欄,然後獲取相關的文章ID即可。完全過濾掉無關的所有數據,提高效率!
elasticsearch的索引和Lucene的索引對比
在elasticsearch中,索引(庫)這個詞被頻繁使用,這就是術語的使用。在elasticsearch中 ,索引被分為多個分片,每份分片是一個Lucene的索引。所以一個elasticsearch索引是由多 個Lucene索引組成的。
到此這篇關於ElasticSearch簡介的文章就介紹到這瞭,更多相關ElasticSearch簡介內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- Java面試重點中的重點之Elasticsearch核心原理
- 在Django中使用ElasticSearch
- DataGrip連接Mysql並創建數據庫的方法實現
- 使用Docker Compose搭建部署ElasticSearch的配置過程
- Elasticsearch6.2服務器升配後的bug(避坑指南)