Java集合-HashMap
概述
①以數組+鏈表+紅黑樹實現。主要用來處理具有鍵值對特征的數據。
②當鏈表長度大於閾值(或者紅黑樹的邊界值,默認為 8 )並且當前數組的長度大於 64 時,此時此索引位置上的所有數據改為使用紅黑樹存儲。
③補充:將鏈表轉換成紅黑樹前會判斷,即便閾值大於 8,但是數組長度小於 64,此時並不會將鏈表變為紅黑樹,而是選擇逬行數組擴容。
④每個Node節點存儲著用來定位數據索引位置的hash值,K鍵,V值以及指向鏈表下一個節點的Node<K,V> next節點組成。
⑤Node是HashMap的內部類,實現瞭Map.Entry接口,本質是一個鍵值對。
⑥這樣做的目的是因為數組比較小,盡量避開紅黑樹結構,這種情況下變為紅黑樹結構,反而會降低效率,因為紅黑樹需要逬行左旋,右旋,變色這些操作來保持平衡。同時數組長度小於64時,搜索時間相對要快些。所以結上所述為瞭提高性能和減少搜索時間,底層閾值大於8並且數組長度大於64時,鏈表才轉換為紅黑樹。

重要的參數
①容量(Capacity)和負載因子(Load factor)
②初始容量:容量是哈希表中桶的個數,初始容量是創建哈希表時的容量。
③負載因子:負載因子是衡量哈希表在自動增加容量之前允許其達到多滿的指標。 默認0.75
④threshold:threshold表示所能容納的鍵值對的臨界值。計算公式為 數組長度 * 負載因子。
⑤size:size是hashmap中實際存在的鍵值對數量。
⑥modCount:用來記錄hashmap內部結構發生變化的次數。
put函數的實現
大致思路:
對key的hashCode()做hash,然後再計算index;
如果沒碰撞直接放到bucket裡;
如果碰撞瞭,以鏈表的形式存在buckets後;
如果碰撞導致鏈表過長(大於等於 TREEIFY_THRESHOLD )就把鏈表轉換成紅黑樹;
如果節點已經存在就替換old value(保證key的唯一性)
如果bucket滿瞭(超過 load factor*current capacity ),就要resize(調整大小)。
get函數的實現
大致思路:
- bucket裡的第一個節點,直接命中;
- 如果有沖突,則通過key.equals(k)去查找對應的entry若為樹,則在樹中通過key.equals(k)查找,O(logn);若為鏈表,則在鏈表中通過key.equals(k)查找,O(n)。
hash函數的實現
//高16bit不變,低16bit和高16bit做瞭一個異或
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
獲取HashMap的元素時,基本分兩步:
- 1.首先根據
hashCode()做hash,然後確定bucket的index; - 2.如果
bucket的節點的key不是我們需要的,則通過keys.equals()在鏈表(紅黑樹)中找。
RESIZE的實現
當put時,如果發現目前的bucket占用程度已經超過瞭Load Factor所希望的比例,那麼就會發生resize。
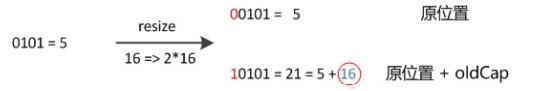
在resize的過程,簡單的說就是把bucket擴充為2倍,之後重
新計算index,把節點再放到新的bucket中。元素的位置要麼是在原位置,要麼是在原位置再移動2次冪的位置。省去瞭重新計算hash值的時間,把之前的沖突的節點分散到新的bucket瞭

什麼時候會使用HashMap?他有什麼特點?
是基於Map接口的實現,存儲鍵值對時,它可以接收null的鍵值,是非同步的,HashMap存儲著Entry(hash, key, value, next)對象。
** 你知道HashMap的工作原理嗎?**
通過hash的方法,通過put和get存儲和獲取對象。存儲對象時,我們將K/V傳給put方法時,它調用hashCode計算hash從而得到bucket位置,進一步存儲,HashMapJava集合——HashMap會根據當前bucket的占用情況自動調整容量(超過 Load Facotr 則resize為原來的2倍)。獲取對象時,我們將K傳給get,它調用hashCode計算hash從而得到bucket位置,並進一步調用equals()方法確定鍵值對。如果發生碰撞的時候,Hashmap通過鏈表將產生碰撞沖突的元素組織起來,在Java 8中,如果一個bucket中碰撞沖突的元素超過某個限制(默認是8),則使用紅黑樹來替換鏈表,從而提高速度。
你知道get和put的原理嗎?equals()和hashCode()的都有什麼作用?
通過對key的hashCode()進行hashing,並計算下標( (n-1) & hash ),從而獲得buckets的位置。如果產生碰撞,則利用key.equals()方法去鏈表或樹中去查找對應的節點。
hash的實現,為什麼要這樣實現?
在Java 1.8的實現中,是通過hashCode()的高16位異或低16位實現的: (h =k.hashCode()) ^ (h >>> 16) ,主要是從速度、功效、質量來考慮的,這麼做可以在bucket的n比較小的時候,也能保證考慮到高低bit都參與到hash的計算中,同時不會有太大的開銷。
如果HashMap的大小超過瞭負載因子( load factor )定義的容量,怎麼辦?
如果超過瞭負載因子(默認0.75),則會重新resize一個原來長度兩倍的HashMap,並且重新調用hash方法。
到此這篇關於Java集合-HashMap的文章就介紹到這瞭,更多相關Java集合HashMap內容請搜索WalkonNet以前的文章或繼續瀏覽下面的相關文章希望大傢以後多多支持WalkonNet!
推薦閱讀:
- 深入理解Java中的HashMap
- HashMap在JDK7與JDK8中的實現過程解析
- HashMap底層實現原理詳解
- Java1.7全網最深入HashMap源碼解析
- Java 中 hashCode() 與 equals() 的關系(面試)